
AUTOMATIQUE
3 Théorie des systèmes
Systèmes et modules
Tous les systèmes considérés dans ce qui suit sont linéaires et à coefficients constants. L'opérateur qui est à la base de la théorie des systèmes à temps continu est la dérivation ∂ (voir ci-dessus), tandis que pour les systèmes à temps discret il s'agit de « l'opérateur d'avance » q : ξ(t) → ξ(t + 1). Posons∇ = (∂ ou q) et R = ℝ[∇]. Un système (qu'il soit à temps continu ou à temps discret) est décrit par une équation de la forme
E(∇)w = 0, (5)
où E(∇) ∈ Rr×k, ce qui généralise la formulation précédente. Il n'y a pas une manière unique de décrire un même système ; il n'y a pas même unicité du nombre de variables et du nombre d'équations dans les différentes descriptions possibles. Par exemple, (6) et (7) ci-dessous
(∇2 + a1∇ + a2)y = (b1∇ + b2)u (6)
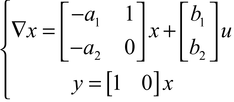
où x = t[x1 x2]est la matrice transposée de[x1 x2], sont deux représentations du même système. Elles ont en commun de définir des R-modules identiques à un isomorphisme près (cf. algèbre linéaire et multilinéaire) : le premier, M1, est engendré par les variables y et u vérifiant (6) ; le second, M2, est engendré par les variables x1, x2 et u vérifiant la première égalité de (7) [d'après la seconde, y appartient à M2]. Un système linéaire s'identifie dès lors (ou est « naturellement associé ») à un R-module M de type fini (c'est-à-dire engendré par un nombre fini d'éléments). Considérons par exemple l'expression (6) de M et soit ȳ l'image canonique de y dans le module quotient M/[u], où[u]désigne le R-module engendré par u. On a (∇2 + a1W + a2) ȳ = 0, et M/[u] = [ȳ]est donc un « module de torsion », car chacun de ses éléments m̄ est un « élément de torsion » [c'est-à-dire vérifie une équation différentielle ou aux différences autonome p(∇)m̄ = 0, 0 ? p(∇) ∈ R, avec dans le cas présent p(∇) = ∇2 + a1∇ + a2]. Cette propriété permet de définir u comme étant l'entrée du système considéré ; dans le cas où u a plusieurs composantes u1, ..., um, le module[u]engendré par ces variables est de plus supposé libre de rang m. La sortie du système est y ; dans le cas général, y peut avoir p composantes y1, ..., yp qui sont des éléments de M.
Représentation d'état
On peut montrer que tout système linéaire et stationnaire admet une représentation dite « d'état », de la forme
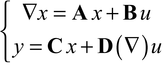
où A ∈ ℝn×n, B ∈ ℝn×m, C ∈ ℝp×n et D(∇) ∈ Rp×m sont appelées respectivement les matrices d'état, d'entrée, de sortie et de « terme direct » et où le vecteur x (ayant n composantes xi) est appelé l'état du système. En revanche, seule une classe bien particulière de systèmes non linéaires admet une représentation d'état, dont la forme est une généralisation de (9). L'équation d'état, à savoir la première équation de (9), est une équation différentielle ou aux différences vectorielle linéaire du premier ordre, ce qui présente des avantages de simplicité ; la seconde équation de (9), appelée l'équation de sortie, montre que la sortie y s'exprime linéairement et uniquement en fonction de l'état (et éventuellement de la commande u) et d'un nombre fini de termes ∇iu, i = 1 ; de sorte que l'état est un résumé du passé du système dans le sens où le second n'influe sur la sortie qu'au travers du premier. Ce système est dit propre si D(∇) ∈ ℝp×m et strictement propre si D = 0. Les systèmes impropres ne sont pas réalisables en pratique (notamment, un système à temps discret impropre est non causal, puisque sa sortie à un instant donné dépend des valeurs futures de l'entrée).[...]
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Hisham ABOU-KANDIL : professeur des Universités
- Henri BOURLÈS : professeur titulaire de chaire (Chaire d'automatisme industriel, Conservatoire national des arts et métiers)
Classification
Autres références
-
APPRENTISSAGE PROFOND ou DEEP LEARNING
- Écrit par Jean-Gabriel GANASCIA
- 2 646 mots
- 1 média
Apprentissage profond, deeplearning en anglais, ou encore « rétropropagation de gradient »… ces termes, quasi synonymes, désignent des techniques d’apprentissage machine (machine learning), une sous-branche de l’intelligence artificielle qui vise à construire automatiquement des connaissances...
-
AUTOMATISATION
- Écrit par Jean VAN DEN BROEK D'OBRENAN
- 11 885 mots
- 12 médias

Célébrer les bienfaits ou dénoncer les méfaits de l'automatisation sous ses formes les plus diverses est l'une des occupations favorites du monde des médias. Aussi « l'homme de la rue » ne manque-t-il pas de sources d'information ; mais lui est-il facile d'opérer la synthèse des connaissances qu'il a...
-
AUTO-ORGANISATION
- Écrit par Henri ATLAN
- 6 258 mots
- 1 média
 On observe, dans des réseaux d'automates en partie aléatoires, des propriétés de classification et de reconnaissance de formes sur la base de critères auto-engendrés, non programmés. Il s'agit là de simulations d'auto-organisation fonctionnelle où ce qui émerge est non seulement une structure macroscopique...
On observe, dans des réseaux d'automates en partie aléatoires, des propriétés de classification et de reconnaissance de formes sur la base de critères auto-engendrés, non programmés. Il s'agit là de simulations d'auto-organisation fonctionnelle où ce qui émerge est non seulement une structure macroscopique... -
BIG DATA
- Écrit par François PÊCHEUX
- 6 148 mots
- 3 médias

L’expression « big data », d’origine américaine et apparue en 1997, désigne un volume très important de données numériques ainsi que les techniques et outils informatiques permettant de les manipuler efficacement afin de leur donner du sens. Traduite en français par « mégadonnées » ou encore «...
- Afficher les 14 références
