
AUTOMATIQUE
Article modifié le
5 Identification
Il existe de nombreuses approches pour identifier un système, dont l'une des plus pertinentes est l'identification paramétrique. C'est à celle-ci que nous limiterons le bref exposé qui suit. Les systèmes considérés sont linéaires stationnaires à temps discret. Ils sont supposés être des filtres causaux et stables, représentés par leur « fonction de transfert » F(q—1) [où q—1 est l'opérateur de retard], qui est à interpréter ici comme l'opérateur de convolution associé. Considérons le modèle M défini par
y(t) = G(q—1, θ) u(t) + H(q—1, θ) w(t) (23)
où le vecteur de paramètres θ est une variable aléatoire à valeurs dans ℝN et w est un bruit blanc à temps discret (c'est-à-dire une suite de variables aléatoires réelles, indépendantes et centrées, de variance E[w(t)2] = σ2 : cf. calcul des probabilités) ; on suppose que le filtre G(q—1, θ) est strictement causal, que H(q—1, θ) est bicausal, bistable et vérifiant H(0, θ) = 1 (ceci sans perte de généralité grâce au « théorème de factorisation spectrale causale directe et inverse ») et que w(t) est indépendant de θ et des entrées u(ô) [cette dernière hypothèse excluant le cas où l'on identifie un système en boucle fermée] ; G et H sont des fractions rationnelles. Soit le système à identifier Σ ayant pour équation
y(t) = Ĝ(q—1) u(t) + Ĥ(q—1) w(t), où Ĥ(0) = 1.
Ce système est dit identifiable à l'aide du modèle M s'il existe une valeur uniquevθ de θ telle que G(q—1, vθ) = Ĝ(q—1) et H(q—1, vθ) = Ĥ(q—1).
Soit Ft—1 la tribu engendrée par les variables aléatoires y(t — i), u(t — i), i = 1, et soit la prédiction optimaleŷ(t | t — 1) = E [y(t) | Ft—1, θ]. Intuitivement, il s'agit de la meilleure prédiction que l'on puisse faire à l'instant t de y(t) sur la base du modèle M, connaissant uniquement les entrées et les sorties passées, et sous l'hypothèse que le paramètre a pour valeur θ. On montre que

La méthode d'identification consiste à minimiser.
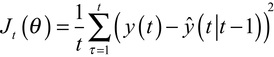
dont le second membre est linéaire par rapport à θ, de la forme tΦ(t — 1)θ ; l'expression (25) est appelée une régression linéaire et le modèle M défini par (23) est dit de type « ARX ». Dans ce cas, la minimisation de Jt(θ) est le « problème des moindres carrés » dont la solution est le résultat d'un calcul explicite qui peut être mis sous forme récursive.
Soit eθ (t) la valeur de θ pour laquelle le critère Jt(θ) est minimum (en supposant que cette valeur existe et soit unique). Supposons le système Σ identifiable à l'aide du modèle M et soit vθ la « vraie valeur » du paramètre. L'estimateur eθ(t) est dit consistant si
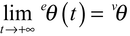
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Hisham ABOU-KANDIL : professeur des Universités
- Henri BOURLÈS : professeur titulaire de chaire (Chaire d'automatisme industriel, Conservatoire national des arts et métiers)
Classification
Autres références
-
APPRENTISSAGE PROFOND ou DEEP LEARNING
- Écrit par Jean-Gabriel GANASCIA
- 2 646 mots
- 1 média
Apprentissage profond, deeplearning en anglais, ou encore « rétropropagation de gradient »… ces termes, quasi synonymes, désignent des techniques d’apprentissage machine (machine learning), une sous-branche de l’intelligence artificielle qui vise à construire automatiquement des connaissances...
-
AUTOMATISATION
- Écrit par Jean VAN DEN BROEK D'OBRENAN
- 11 885 mots
- 12 médias

Célébrer les bienfaits ou dénoncer les méfaits de l'automatisation sous ses formes les plus diverses est l'une des occupations favorites du monde des médias. Aussi « l'homme de la rue » ne manque-t-il pas de sources d'information ; mais lui est-il facile d'opérer la synthèse des connaissances qu'il a...
-
AUTO-ORGANISATION
- Écrit par Henri ATLAN
- 6 258 mots
- 1 média
 On observe, dans des réseaux d'automates en partie aléatoires, des propriétés de classification et de reconnaissance de formes sur la base de critères auto-engendrés, non programmés. Il s'agit là de simulations d'auto-organisation fonctionnelle où ce qui émerge est non seulement une structure macroscopique...
On observe, dans des réseaux d'automates en partie aléatoires, des propriétés de classification et de reconnaissance de formes sur la base de critères auto-engendrés, non programmés. Il s'agit là de simulations d'auto-organisation fonctionnelle où ce qui émerge est non seulement une structure macroscopique... -
BIG DATA
- Écrit par François PÊCHEUX
- 6 148 mots
- 3 médias

L’expression « big data », d’origine américaine et apparue en 1997, désigne un volume très important de données numériques ainsi que les techniques et outils informatiques permettant de les manipuler efficacement afin de leur donner du sens. Traduite en français par « mégadonnées » ou encore «...
- Afficher les 14 références
Voir aussi
- COMMANDE
- ASSERVIS SYSTÈMES
- RÉGULATEUR
- TRANSFERT FONCTION DE
- MATRICE, mathématiques
- ÉQUATION LINÉAIRE
- MODULE, mathématiques
- PÔLE, mathématiques
- TEMPS RÉEL
- VALEUR PROPRE
- BOUCLE, automatique
- SYSTÈMES À ÉVÉNEMENTS DISCRETS, automatique
- GRAFCET (graphe fonctionnel de commande des étapes et transitions)
- SYSTÈMES CONTINUS, automatique
- ROBUSTESSE, automatique
- COMMANDE ADAPTATIVE, automatique
- COMMANDABILITÉ, automatique
- KALMAN CRITÈRE DE
- OBSERVABILITÉ, automatique
- NYQUIST CRITÈRE DE
- IDENTIFICATION, automatique
- FEEDBACK ou RÉTROACTION
- NYQUIST LIEU DE
- APPROXIMATION
- SYSTÈMES THÉORIE DES
- PERFORMANCES, technologie
- NON-LINÉAIRE SYSTÈME
- MODÉLISATION
- SYSTÈMES SCIENCE DES
- MODÈLE, mathématiques
