
BIG DATA
Caractéristiques des données du big data
Les données du big data sont donc en perpétuelle expansion (plus ou moins contrôlée), sont acquises à travers de multiples canaux (trafic Internet généré, capteurs…) à des rythmes très différents (de la nanoseconde pour les transactions boursières au jour ou à l’année pour les mesures sur des données démographiques ou sociétales) et sont de différentes natures (texte, vidéo, image, son, biométrie, etc.). Elles sont aussi acquises dans un contexte qui peut, le cas échéant, dégrader la quantité et la qualité de l’information associée. Dans un monde où les fausses nouvelles (fake news) pullulent, on pourra ainsi accorder un degré de confiance en fonction de l’émetteur de la donnée.
Après prétraitement (formatage, conversion, filtrage), les données du big data sont analysées à l’aide d’algorithmes complexes permettant de les identifier, de les classer de manière automatique, sans intervention humaine. Afin de définir aussi précisément que possible la taille de l’espace dans lequel s’opèrent ces analyses, plusieurs générations de modèles de représentation des données du big data ont successivement vu le jour. Le plus connu est le modèle 3V (pour volume, vitesse, variété). Le modèle 4V ajoute la véracité (une donnée est liée à un facteur de vraisemblance) aux trois précédentes caractéristiques. Au gré des inspirations du marketing, d’autres V (par exemple pour valeur, qui associe un coût financier à l’information) ont également fait leur apparition.
Volume des données
Le volume des données est certainement ce qui caractérise le mieux l’expression « big data ». Il suffit d’égrener certaines grandeurs pour apprécier le volume colossal des données générées : 7 milliards d’individus sur Terre, 6 milliards de possesseurs de téléphones portables ou de smartphones, 100 à 120 téraoctets de données nécessaires pour rendre compte de l’activité d’une grande entreprise mondiale, 150 exaoctets pour représenter l’ensemble des données médicales de la population mondiale, 30 milliards de contenus Web différents, 500 millions de capteurs biomédicaux portés à même les personnes, 400 millions de messages twitter échangés par jour entre les 200 millions d’utilisateurs, plus de 4 milliards d’heures de contenus vidéo consultées sur YouTube par mois.
Vitesse d’acquisition des données ou vélocité
Une autre caractéristique des données du big data est la vitesse d’acquisition de celles-ci, terme impropre qui représente en réalité la fréquence (nombre d’événements par unité de temps) à laquelle les données sont générées et stockées. Dans un monde qui change à un rythme effréné et où la nouvelle information chasse impitoyablement l’ancienne, les données n’ont de sens que si leur date de production est connue et récente, et que le temps pour les traiter est court et compatible avec la réactivité attendue. Nous nous sommes habitués à recevoir plus de données dans des temps toujours plus courts, et à ce que ces données soient traitées en temps réel pour être immédiatement exploitables.
Variété de données
Les données de l’informatique traditionnelle sont généralement le résultat de transactions informatiques (insertion ou recherche dans une base de données) et sont de taille et de type limités aisément exploitables par un ordinateur (entiers naturels, nombres réels, chaînes de caractères). Tous les autres types de données, comme les images par exemple, sont soit stockés sous forme de références (on stocke dans la base le chemin d’accès au fichier mais ce dernier n’est pas directement enregistré dans la base), soit sous forme d’un type générique – l’amas ou blob, pour binary large object, stocké dans la base mais très difficilement exploitable. Les données du big data sont de nature encore plus diverse, plus[...]
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- François PÊCHEUX : professeur, Sorbonne université
Classification
Médias

Centre de données
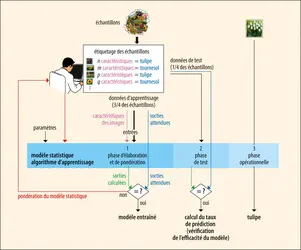
Apprentissage supervisé
Encyclopædia Universalis France
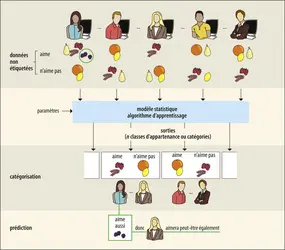
Apprentissage non supervisé
Encyclopædia Universalis France
Autres références
-
APPRENTISSAGE PROFOND ou DEEP LEARNING
- Écrit par Jean-Gabriel GANASCIA
- 2 645 mots
- 1 média
 L’apprentissage supervisé recourt à des techniques variées fondées sur la logique ou la statistique et s’inspirant de modèles psychologiques, physiologiques ou éthologiques. Parmi celles-ci, des techniques anciennes reposant sur un modèle très approximatif du tissu cérébral – les réseaux...
L’apprentissage supervisé recourt à des techniques variées fondées sur la logique ou la statistique et s’inspirant de modèles psychologiques, physiologiques ou éthologiques. Parmi celles-ci, des techniques anciennes reposant sur un modèle très approximatif du tissu cérébral – les réseaux... -
CARTOGRAPHIE CELLULAIRE DU CERVEAU
- Écrit par Jean-Gaël BARBARA
- 2 990 mots
- 1 média
big data. Dans tous les cas, l’alignement des bases de données hétérogènes, dynamiques, utilisées et alimentées en ligne en continu, est réalisé en établissant des correspondances entre des ensembles distincts. -
CONSOMMATION - Comportement du consommateur
- Écrit par Bernard DUBOIS et Marc VANHUELE
- 9 030 mots
- 1 média

Par « comportement du consommateur », on entend l'ensemble des comportements qui se rapportent à l'acquisition de biens et services. On y inclut l’exposition à des messages commerciaux et à d’autres types d’information, l'expérience de l’utilisation des biens et services achetés et l'abandon éventuel...
-
HISTOIRE GLOBALE
- Écrit par Pierre-Yves SAUNIER
- 5 932 mots
- 1 média
 La montée en puissance des ressources en données massives (big data) et de leur possibilité de traitement approfondit cette fracture méthodologique. Le Collaborative for Historical Information and Analysis (CHIA, fondé en 2011, université de Pittsburgh), le projet Pulotu (Database of Pacific Religions),...
La montée en puissance des ressources en données massives (big data) et de leur possibilité de traitement approfondit cette fracture méthodologique. Le Collaborative for Historical Information and Analysis (CHIA, fondé en 2011, université de Pittsburgh), le projet Pulotu (Database of Pacific Religions),... - Afficher les 8 références
