
BIG DATA
Les aspects matériels du big data
Les algorithmes et les outils logiciels liés au big data s’exécutent sur de puissantes machines fortement connectées en réseaux, les centres de données ou data centers. Ces outils ont pour principale fonction d’analyser de grands ensembles de données possiblement disparates ou entachées d’erreurs pour y trouver un sens, une loi d’évolution. La manière de procéder est à peu près toujours la même : « décomposer pour régner » (divide and conquer). L’analyse globale est découpée en sous-analyses indépendantes traitées en parallèle par des ordinateurs nœuds de calcul, ce qui correspond à la phase de déploiement (map en anglais) du calcul. Les résultats sont ensuite calculés indépendamment par ces nœuds de calcul, puis rassemblés et agglomérés pour être réduits (data reduction) à un résultat, la loi d’évolution recherchée. Cette technologie, connue sous le nom de MapReduce, a été développée avec succès par la société américaine Google, en utilisant l’environnement de développement libre Hadoop, qui permet de créer facilement des applications réparties sur les différents centres de données. Remplacé en 2014 par Spark, plus rapide, MapReduce a inspiré plusieurs autres acteurs majeurs comme Oracle ou Microsoft, qui s’appuient sur leur propre solution de cloud computing (« informatique en nuage ») pour un service identique.
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- François PÊCHEUX : professeur, Sorbonne université
Classification
Médias

Centre de données
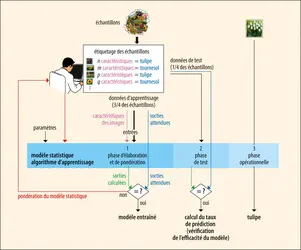
Apprentissage supervisé
Encyclopædia Universalis France
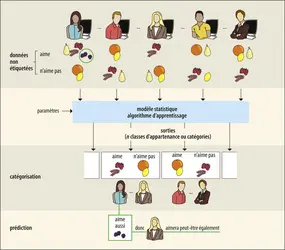
Apprentissage non supervisé
Encyclopædia Universalis France
Autres références
-
APPRENTISSAGE PROFOND ou DEEP LEARNING
- Écrit par Jean-Gabriel GANASCIA
- 2 645 mots
- 1 média
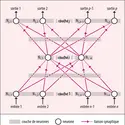 L’apprentissage supervisé recourt à des techniques variées fondées sur la logique ou la statistique et s’inspirant de modèles psychologiques, physiologiques ou éthologiques. Parmi celles-ci, des techniques anciennes reposant sur un modèle très approximatif du tissu cérébral – les réseaux...
L’apprentissage supervisé recourt à des techniques variées fondées sur la logique ou la statistique et s’inspirant de modèles psychologiques, physiologiques ou éthologiques. Parmi celles-ci, des techniques anciennes reposant sur un modèle très approximatif du tissu cérébral – les réseaux... -
CARTOGRAPHIE CELLULAIRE DU CERVEAU
- Écrit par Jean-Gaël BARBARA
- 2 990 mots
- 1 média
big data. Dans tous les cas, l’alignement des bases de données hétérogènes, dynamiques, utilisées et alimentées en ligne en continu, est réalisé en établissant des correspondances entre des ensembles distincts. -
CONSOMMATION - Comportement du consommateur
- Écrit par Bernard DUBOIS et Marc VANHUELE
- 9 030 mots
- 1 média

Par « comportement du consommateur », on entend l'ensemble des comportements qui se rapportent à l'acquisition de biens et services. On y inclut l’exposition à des messages commerciaux et à d’autres types d’information, l'expérience de l’utilisation des biens et services achetés et l'abandon éventuel...
-
HISTOIRE GLOBALE
- Écrit par Pierre-Yves SAUNIER
- 5 932 mots
- 1 média
 La montée en puissance des ressources en données massives (big data) et de leur possibilité de traitement approfondit cette fracture méthodologique. Le Collaborative for Historical Information and Analysis (CHIA, fondé en 2011, université de Pittsburgh), le projet Pulotu (Database of Pacific Religions),...
La montée en puissance des ressources en données massives (big data) et de leur possibilité de traitement approfondit cette fracture méthodologique. Le Collaborative for Historical Information and Analysis (CHIA, fondé en 2011, université de Pittsburgh), le projet Pulotu (Database of Pacific Religions),... - Afficher les 8 références
