
BIG DATA
Les aspects algorithmiques et logiciels du big data
Les logiciels de gestion de bases de données traditionnels s’appuient sur les mathématiques relatives à la théorie des ensembles pour appliquer des algorithmes de recherche exhaustifs et déterministes (pour un algorithme donné, les mêmes données initiales impliquent le même résultat en sortie) sur des données fortement structurées (en tables contenant des lignes d’informations pertinentes appelées enregistrements ou tuples, en collections de dimensions finies), cela afin d’isoler les enregistrements de la base qui correspondent à un critère de recherche donné. Les méthodes traditionnelles de modélisation de données ainsi que les systèmes de gestion de base de données ont été conçus pour des volumes de données très inférieurs à ceux du big data. L’informatique décisionnelle classique, celle des bases de données, repose sur l’utilisation de modèles relativement cloisonnés, individuels, représentant le monde. Appelés modèles entité-relation ou entité-association, ils décrivent des tables contenant des lignes cohérentes de donnéesen interaction les unes avec les autres. Les algorithmes de cette informatique agissent sur des données denses en information, sémantiquement univoques, et s’appuient sur des index et des clés pour connecter les enregistrements entre eux.
À l’inverse, les techniques d’analyse du big data s’appuient sur la notion de fouille de données (data mining) pour extraire de l’information ou de la connaissance à partir d’une multitude de données au moyen de méthodes automatisées. La fouille de données s’appuie elle-même sur une suite d’algorithmes dont le rôle est d’identifier des motifs d’intérêt en fonction de critères de recherche définis préalablement ou réévalués en cours de calcul. L’informatique du big data est celle qui acquiert des zettaoctets de données à partir du monde réel, potentiellement pauvres en information ou bruitées, et qui détermine de manière automatisée et aussi rapide que possible des modèles mathématiques fiables et prédictifs. À l’extrême, on peut considérer que le big data revient à « faire parler les chiffres » et à trouver des réponses à partir d’une quantité phénoménale de données, alors que l’on n'a même pas formulé de question. La dimension exploratoire de la fouille de données fait que l’on ne sait pas forcément ce que l’on cherche.
Le big data exploite donc d’autres mathématiques que la logique ensembliste, en particulier les statistiques et les probabilités. Les algorithmes utilisés sont ici essentiellement issus de l’intelligence artificielle et de la recherche opérationnelle. Il s’agit ici non plus de rechercher des données spécifiques mais d’appréhender la multitude des informations brutes du monde réel afin de les classifier de manière automatisée (sans intervention humaine), de déterminer des lois d’évolution ou encore un modèle abstrait de ces données. Les techniques d’analyse des données relatives au big data, connues sous le nom de big analytics (« grandes analyses » ou « analyses massives »), mettent ainsi en jeu des algorithmes de calcul fort complexes et généralement autoadaptatifs (capables de tenir compte de leurs propres erreurs). Ils reposent en grande partie sur les progrès réalisés dans le domaine de l’apprentissage automatique (machine learning), encore appelé apprentissage statistique, et de son extension, l’apprentissage profond (deeplearning), qui excelle dans la reconnaissance vocale, la reconnaissance d’images, ou encore le traitement automatique du langage naturel.
Pour un domaine donné, avec son principe général de fonctionnement et ses spécificités, l’objectif principal de l’apprentissage statistique est de mettre au point un modèle formel robuste et suffisamment précis permettant, dans un premier temps de classifier[...]
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- François PÊCHEUX : professeur, Sorbonne université
Classification
Médias

Centre de données
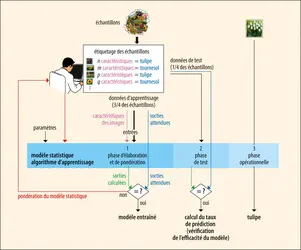
Apprentissage supervisé
Encyclopædia Universalis France
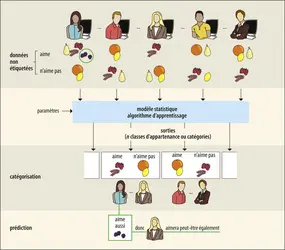
Apprentissage non supervisé
Encyclopædia Universalis France
Autres références
-
APPRENTISSAGE PROFOND ou DEEP LEARNING
- Écrit par Jean-Gabriel GANASCIA
- 2 645 mots
- 1 média
 L’apprentissage supervisé recourt à des techniques variées fondées sur la logique ou la statistique et s’inspirant de modèles psychologiques, physiologiques ou éthologiques. Parmi celles-ci, des techniques anciennes reposant sur un modèle très approximatif du tissu cérébral – les réseaux...
L’apprentissage supervisé recourt à des techniques variées fondées sur la logique ou la statistique et s’inspirant de modèles psychologiques, physiologiques ou éthologiques. Parmi celles-ci, des techniques anciennes reposant sur un modèle très approximatif du tissu cérébral – les réseaux... -
CARTOGRAPHIE CELLULAIRE DU CERVEAU
- Écrit par Jean-Gaël BARBARA
- 2 990 mots
- 1 média
big data. Dans tous les cas, l’alignement des bases de données hétérogènes, dynamiques, utilisées et alimentées en ligne en continu, est réalisé en établissant des correspondances entre des ensembles distincts. -
CONSOMMATION - Comportement du consommateur
- Écrit par Bernard DUBOIS et Marc VANHUELE
- 9 030 mots
- 1 média

Par « comportement du consommateur », on entend l'ensemble des comportements qui se rapportent à l'acquisition de biens et services. On y inclut l’exposition à des messages commerciaux et à d’autres types d’information, l'expérience de l’utilisation des biens et services achetés et l'abandon éventuel...
-
HISTOIRE GLOBALE
- Écrit par Pierre-Yves SAUNIER
- 5 932 mots
- 1 média
 La montée en puissance des ressources en données massives (big data) et de leur possibilité de traitement approfondit cette fracture méthodologique. Le Collaborative for Historical Information and Analysis (CHIA, fondé en 2011, université de Pittsburgh), le projet Pulotu (Database of Pacific Religions),...
La montée en puissance des ressources en données massives (big data) et de leur possibilité de traitement approfondit cette fracture méthodologique. Le Collaborative for Historical Information and Analysis (CHIA, fondé en 2011, université de Pittsburgh), le projet Pulotu (Database of Pacific Religions),... - Afficher les 8 références
