CODE GÉNÉTIQUE
Article modifié le
L'ADN (pour acide désoxyribonucléique) est une macromolécule linéaire, support matériel de l’hérédité de tous les organismes vivants, à l’exception de quelques virus. Une molécule d’ADN est constituée de l'enchaînement de quatre motifs moléculaires, les nucléotides. Cet enchaînement étant séquentiel, on le représente comme un texte écrit avec un alphabet de quatre lettres, notées A, T, G et C – du nom des quatre sortes de « bases » qui spécifient les nucléotides : adénine, thymine, guanine et cytosine. Ce texte représente la séquence de l’ADN considéré.
Physiquement, cette molécule est faite de deux brins enroulés l’un sur l’autre selon une loi de complémentarité entre les nucléotides des brins appariés : en face d'un A on trouve toujours un T sur l’autre brin ; en face d'un C, un G ; d'un T, un A ; d'un G, un C.
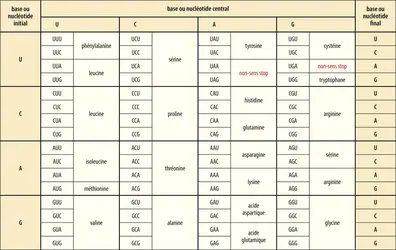
Code génétique
Encyclopædia Universalis France
La séquence de l'ADN a de nombreuses fonctions, dont en particulier celle de définir localement des segments qui codent les protéines : les gènes. Les protéines sont, là encore, des enchaînements de modules de base appelés acides aminés, mais cette fois de vingt types différents. Un gène correspond donc à l'enchaînement local des lettres du texte de l'ADN qui définit l'enchaînement des acides aminés de la protéine. On parle de colinéarité entre les deux séquences : la règle qui permet la correspondance entre le texte de l'ADN et le texte des protéines est le « code génétique ».
Un décodage opérant sur trois niveaux
Comment passe-t-on sans erreur d’un texte écrit dans un alphabet à quatre lettres à un texte utilisant un alphabet à vingt lettres ? Ce changement de code est assuré par un intermédiaire entre l'ADN et les protéines, une molécule d’ARN (pour acide ribonucléique) copiée exactement sur l'ADN du gène qui doit être traduit en protéine : cet ARN est appelé ARN messager (ARNm). L’information génétique y est toujours codée par un alphabet nucléotidique à quatre lettres ATUG, dans lequel U (pour uracile) remplace le T de l’ADN. On se trouve donc toujours devant la nécessité d’un code et d’un « traducteur » pour passer de l’ARNm à la protéine. Concernant le code de correspondance, l’association de 2 bases prises parmi les 4, génère seulement 16 combinaisons, chiffre insuffisant devant les 20 acides aminés ; mais, si l'on en prend 3, on en trouve 64 (43), nombre en excès !
Le code de correspondance (quasi) universel entre une séquence d’ARN et un acide aminé fut découvert au début des années 1960 : à chaque suite de trois nucléotides (encore appelée codon) de l'ARN copié à partir du texte de l'ADN correspond un acide aminé. Comme les nucléotides sont lus trois par trois, il est essentiel que le début de la lecture soit bien spécifié, pour que le décodage s’effectue selon le bon cadre de lecture : un décalage d’un seul ou de deux nucléotides changerait la séquence de la protéine. Un codon dit d’initiation indique donc précisément le début de la protéine à traduire, et d’autres, dits de terminaison ou codons stop, en indiquent la fin.

Puisqu’il existe 64 codons disponibles, plusieurs d’entre eux sont « synonymes » : ils spécifient le même acide aminé ; on dit que le code est dégénéré. La plupart des synonymes ne diffèrent que par la troisième base du triplet, celui-ci étant lu de gauche (côté 5') à droite (côté 3').
Concernant la traduction – le décodage –, c'est sans doute à Francis Crick qu'on doit l'idée qu'il fallait un « adaptateur », entre l'ARN messager et la protéine. Il s'agit d'une classe particulière d'ARN, les ARN de transfert, au nombre de 20. Une partie de leur molécule reconnaît spécifiquement un codon de l’ARNm par un triplet complémentaire (l’anticodon), et une autre porte un acide aminé précis qu'ils transfèrent à la chaîne de la protéine en cours de construction quand le codon correspondant se présente sur la machine de synthèse de la protéine, à savoir le ribosome : le décodage et la synthèse s’effectuent ainsi par glissement le long de codons successifs.
La correspondance physique entre l'ADN et les protéines, leur colinéarité, peut donc se représenter de façon abstraite comme la conséquence d’une suite de trois « règles de réécriture » : la copie de l’ADN en ARN messager ; la reconnaissance des codons de l’ARNm par les anticodons des ARN de transfert, dont une autre région porte l’acide aminé concerné ; enfin, l’assemblage séquentiel de ces acides aminés.
Accédez à l'intégralité de nos articles
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Antoine DANCHIN : directeur de recherche au CNRS, professeur à l'Institut Pasteur
- Encyclopædia Universalis : services rédactionnels de l'Encyclopædia Universalis
Classification
Média
Code génétique
Encyclopædia Universalis France
Autres références
-
DÉCRYPTAGE DU CODE GÉNÉTIQUE
- Écrit par Nicolas CHEVASSUS-au-LOUIS
- 223 mots
- 1 média

Au début des années 1960, l'Américain Marshall W. Nirenberg découvre que l'addition d'un acide ribonucléique messager (ARNm) constitué uniquement d'uridine (U, un des quatre nucléotides) à un extrait bactérien suffit à déclencher la synthèse d'une protéine composée uniquement de phénylalanine....
-
ADN (acide désoxyribonucléique) ou DNA (deoxyribonucleic acid)
- Écrit par Michel DUGUET , Encyclopædia Universalis , David MONCHAUD et Michel MORANGE
- 10 074 mots
- 10 médias
 ...protéines, puisque l'on savait depuis peu que les enzymes n'étaient que des protéines) : à chaque gène correspondait une enzyme et à chaque enzyme un gène. C'est à George Gamow – physicien et astrophysicien américain, célèbre pour avoir prédit, avant qu'on ne l'observe expérimentalement, l'existence...
...protéines, puisque l'on savait depuis peu que les enzymes n'étaient que des protéines) : à chaque gène correspondait une enzyme et à chaque enzyme un gène. C'est à George Gamow – physicien et astrophysicien américain, célèbre pour avoir prédit, avant qu'on ne l'observe expérimentalement, l'existence... -
BIOCHIMIE
- Écrit par Pierre KAMOUN
- 3 881 mots
- 5 médias
 ...de bases du messager, copie servile de l'ADN. La seconde étape de la synthèse protéique est celle de la traduction du message génétique en protéine. Le code génétique entièrement élucidé par Nirenberg, Khorana et Ochoa en 1965 s'est révélé universel, valable aussi bien pour “la bactérie que pour l'éléphant”....
...de bases du messager, copie servile de l'ADN. La seconde étape de la synthèse protéique est celle de la traduction du message génétique en protéine. Le code génétique entièrement élucidé par Nirenberg, Khorana et Ochoa en 1965 s'est révélé universel, valable aussi bien pour “la bactérie que pour l'éléphant”.... -
BIOLOGIE - La biologie moléculaire
- Écrit par Gabriel GACHELIN
- 7 405 mots
- 8 médias
 ...bases, 3 entre C et G, 2 entre A et T. Une molécule d'ADN est donc constituée de deux chaînes de séquences complémentaires en bases mais de sens opposé. Ainsi, le code de l'hérédité se trouve dans la séquence des bases. Le gène, toujours unité de fonction et de recombinaison, devient un morceau de cette...
...bases, 3 entre C et G, 2 entre A et T. Une molécule d'ADN est donc constituée de deux chaînes de séquences complémentaires en bases mais de sens opposé. Ainsi, le code de l'hérédité se trouve dans la séquence des bases. Le gène, toujours unité de fonction et de recombinaison, devient un morceau de cette... -
CELLULE - L'organisation
- Écrit par Pierre FAVARD
- 11 031 mots
- 15 médias
 ...spécifie un acide aminé ; la table de correspondance entre les 64 codons et les 20 acides aminés existant dans la panoplie moléculaire du vivant étant le code génétique. Afin que les ARNm (séquence de nucléotides) puissent être traduits en polypeptides (séquence d'acides aminés) par les ribosomes, il est...
...spécifie un acide aminé ; la table de correspondance entre les 64 codons et les 20 acides aminés existant dans la panoplie moléculaire du vivant étant le code génétique. Afin que les ARNm (séquence de nucléotides) puissent être traduits en polypeptides (séquence d'acides aminés) par les ribosomes, il est... - Afficher les 18 références
Voir aussi
- NUCLÉOTIDES
- CODON, biologie moléculaire
- ARN DE TRANSFERT ou ARNt
- ARN MESSAGER ou ARNm
- RÉPLICATION, biologie moléculaire
- TRANSCRIPTION, biologie moléculaire
- TRADUCTION, biologie moléculaire
- BIOLOGIE MOLÉCULAIRE
- PROTÉINES BIOSYNTHÈSE DES
- NUCLÉOTIDIQUE SÉQUENCE
- GÉNÉTIQUE MOLÉCULAIRE
- PROTÉINES
- BASES NUCLÉIQUES ou BASES AZOTÉES
