CODE GÉNÉTIQUE
Article modifié le
Peut-on modifier le code génétique ?
e code génétique étant quasi universel, tout comme la machinerie qui l’utilise, peut-on établir un code génétique fonctionnel différent ? Une réussite en ce sens permettrait de produire des protéines ayant par exemple incorporé des acides aminés non naturels ou modifiés, et de fabriquer ainsi des molécules ayant des propriétés biologiques – et pharmacologiques – nouvelles. Ce domaine de recherche est en pleine expansion depuis les années 2000. On peut y distinguer deux tendances.
Tout d’abord, la chimie de l’ADN permet depuis longtemps d’introduire dans ce dernier des bases modifiées. On a pu construire un organisme – ici un minichromosome (plasmide) du colibacille Escherichia coli – dont l’ADN contient, en plus des habituels A, T, C et G, une paire de bases de synthèse non naturelles. Le code génétique du plasmide est désormais à six lettres au lieu de quatre (alphabet génétique augmenté). Ce plasmide est capable de se répliquer normalement et d’être copié de même. Différemment, on peut modifier les ARN de transfert pour leur faire reconnaître un code à quatre lettres. Ces premiers succès ne signifient nullement que l’on peut produire ainsi des protéines contenant des acides aminés non naturels : il faudrait pour cela modifier profondément la machinerie de décodage.

Cette production est en revanche réalisée – seconde tendance de la recherche – par reprogrammation du code permettant la charge d’aminoacides non naturels sur un ARN de transfert, en se servant d’enzymes de charge des ARNm de faible spécificité vis-à-vis de l’acide aminé, les flexizymes. De nombreuses protéines contenant des acides aminés non naturels ou des acides aminés modifiés par des radicaux chimiques ont pu être ainsi produites dans différents types de cellules.
Ces expériences (qui relèvent des genetic code expansion, ou genetic code engineeringde la recherche anglo-saxonne) montrent que le code génétique peut être modifié en divers points de la séquence de traduction. Cependant, pour impressionnants qu’ils soient, ces résultats n’indiquent pas que l’on puisse produire de « nouveaux organismes vivants », des aliens en quelque sorte, utilisant un code et (ou) des acides aminés différents – ce qui est le but de la xénobiologie. Cela supposerait en effet la reconfiguration de l’ensemble des voies métaboliques concernées.
Accédez à l'intégralité de nos articles
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Antoine DANCHIN : directeur de recherche au CNRS, professeur à l'Institut Pasteur
- Encyclopædia Universalis : services rédactionnels de l'Encyclopædia Universalis
Classification
Média
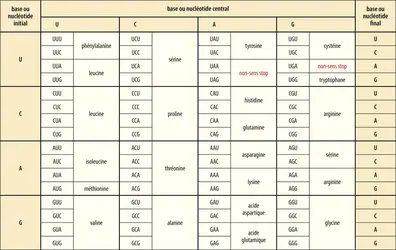
Code génétique
Encyclopædia Universalis France
Autres références
-
DÉCRYPTAGE DU CODE GÉNÉTIQUE
- Écrit par Nicolas CHEVASSUS-au-LOUIS
- 223 mots
- 1 média

Au début des années 1960, l'Américain Marshall W. Nirenberg découvre que l'addition d'un acide ribonucléique messager (ARNm) constitué uniquement d'uridine (U, un des quatre nucléotides) à un extrait bactérien suffit à déclencher la synthèse d'une protéine composée uniquement de phénylalanine....
-
ADN (acide désoxyribonucléique) ou DNA (deoxyribonucleic acid)
- Écrit par Michel DUGUET , Encyclopædia Universalis , David MONCHAUD et Michel MORANGE
- 10 074 mots
- 10 médias
 ...protéines, puisque l'on savait depuis peu que les enzymes n'étaient que des protéines) : à chaque gène correspondait une enzyme et à chaque enzyme un gène. C'est à George Gamow – physicien et astrophysicien américain, célèbre pour avoir prédit, avant qu'on ne l'observe expérimentalement, l'existence...
...protéines, puisque l'on savait depuis peu que les enzymes n'étaient que des protéines) : à chaque gène correspondait une enzyme et à chaque enzyme un gène. C'est à George Gamow – physicien et astrophysicien américain, célèbre pour avoir prédit, avant qu'on ne l'observe expérimentalement, l'existence... -
BIOCHIMIE
- Écrit par Pierre KAMOUN
- 3 881 mots
- 5 médias
 ...de bases du messager, copie servile de l'ADN. La seconde étape de la synthèse protéique est celle de la traduction du message génétique en protéine. Le code génétique entièrement élucidé par Nirenberg, Khorana et Ochoa en 1965 s'est révélé universel, valable aussi bien pour “la bactérie que pour l'éléphant”....
...de bases du messager, copie servile de l'ADN. La seconde étape de la synthèse protéique est celle de la traduction du message génétique en protéine. Le code génétique entièrement élucidé par Nirenberg, Khorana et Ochoa en 1965 s'est révélé universel, valable aussi bien pour “la bactérie que pour l'éléphant”.... -
BIOLOGIE - La biologie moléculaire
- Écrit par Gabriel GACHELIN
- 7 405 mots
- 8 médias
 ...bases, 3 entre C et G, 2 entre A et T. Une molécule d'ADN est donc constituée de deux chaînes de séquences complémentaires en bases mais de sens opposé. Ainsi, le code de l'hérédité se trouve dans la séquence des bases. Le gène, toujours unité de fonction et de recombinaison, devient un morceau de cette...
...bases, 3 entre C et G, 2 entre A et T. Une molécule d'ADN est donc constituée de deux chaînes de séquences complémentaires en bases mais de sens opposé. Ainsi, le code de l'hérédité se trouve dans la séquence des bases. Le gène, toujours unité de fonction et de recombinaison, devient un morceau de cette... -
CELLULE - L'organisation
- Écrit par Pierre FAVARD
- 11 031 mots
- 15 médias
 ...spécifie un acide aminé ; la table de correspondance entre les 64 codons et les 20 acides aminés existant dans la panoplie moléculaire du vivant étant le code génétique. Afin que les ARNm (séquence de nucléotides) puissent être traduits en polypeptides (séquence d'acides aminés) par les ribosomes, il est...
...spécifie un acide aminé ; la table de correspondance entre les 64 codons et les 20 acides aminés existant dans la panoplie moléculaire du vivant étant le code génétique. Afin que les ARNm (séquence de nucléotides) puissent être traduits en polypeptides (séquence d'acides aminés) par les ribosomes, il est... - Afficher les 18 références
Voir aussi
- NUCLÉOTIDES
- CODON, biologie moléculaire
- ARN DE TRANSFERT ou ARNt
- ARN MESSAGER ou ARNm
- RÉPLICATION, biologie moléculaire
- TRANSCRIPTION, biologie moléculaire
- TRADUCTION, biologie moléculaire
- BIOLOGIE MOLÉCULAIRE
- PROTÉINES BIOSYNTHÈSE DES
- NUCLÉOTIDIQUE SÉQUENCE
- GÉNÉTIQUE MOLÉCULAIRE
- PROTÉINES
- BASES NUCLÉIQUES ou BASES AZOTÉES
