GÉNÉTIQUE
Article modifié le
La génétique moléculaire
Grâce à la technologie de l'ADN recombinant, il est maintenant possible d'obtenir « à volonté », d'analyser et de manipuler n'importe quel gène de n'importe quel organisme vivant. Du fait de sa « puissance », le génie génétique devait bientôt quitter les laboratoires où il avait vu le jour pour pénétrer, et modifier, une très large gamme de secteurs d'activité : la quasi-totalité de la biologie, la médecine, la médecine légale, l'industrie, l'agriculture... On peut dire que l'ADN, source de l'hérédité, a entraîné des changements dans les consciences et les sociétés... ce qui ne va pas sans poser de redoutables questions au niveau de l'éthique et de la morale... voire de la politique des États.
Les molécules informationnelles dans l'hérédité

Molécule d'ADN
Encyclopædia Universalis France

Les gènes sont constitués de brins d'acides nucléiques : acide désoxyribonucléique presque toujours, acide ribonucléique dans certains virus des animaux (rétrovirus, virus de la rougeole, par exemple) et des plantes. Les brins d'acides nucléiques sont composés d'une succession de nucléotides unis les uns aux autres par des liaisons phosphodiesters. Chaque nucléotide se compose d'une base qui lui confère une identité (A, C, G, T dans l'ADN ou U dans l'ARN), d'un sucre à 5 atomes de carbone (ribose dans l'ARN, désoxyribose dans l'ADN), et d'acide phosphorique lié à l'hydroxyle 5′ du sucre. L'ADN est le plus souvent sous la forme d'un double brin s'appariant avec précision grâce à la complémentarité des bases, une base purique s'appariant à une base pyrimidique, A avec T et G avec C (fig. 10). Dans l'ADN double brin, qui recèle l'information génétique, le squelette des ponts phosphodiesters est à l'extérieur ; les bases, dirigées vers l'intérieur, forment un empilement de structures moléculaires planes et parallèles dont, dans l'hélice droite habituelle, dite forme B, les axes sont décalés de 34,60 entre deux couples de bases : le double brin d'ADN sous la forme B est donc hélicoïdal, réalisant un tour complet (3600) toutes les 10,4 bases. La synthèse des brins d'ADN dans les cellules se fait toujours par addition d'un nucléotide au niveau de l'extrémité de la chaîne polynucléotidique ayant un radical hydroxyle libre en 3′, radical hydroxyle avec lequel réagit le résidu d' acide phosphorique lié à l'hydroxyle 5′ du nucléotide ajouté lequel aura lui-même un hydroxyle 3′ libre du côté opposé. L'élongation des brins d'acide nucléique est donc polarisée, du fait que la réaction d'élongation se réalise dans le sens « 5′ → 3′ ». Cette polarité permet également de désigner les deux extrémités d'un brin d'acide nucléique (extrémité 5′, signifiant l'extrémité ayant un hydroxyle 5′ libre ou estérifié par un acide phosphorique ; extrémité 3′, signifiant l'extrémité ayant un hydroxyle libre en 3′). Les deux brins d'une double hélice d'ADN sont donc antiparallèles, un brin orienté dans le sens 5′ → 3′ de gauche à droite s'appariant avec son brin complémentaire orienté dans le sens 3′ → 5′. Grâce à la complémentarité des bases, la synthèse de l'ADN est semi-conservative, chaque brin servant de matrice pour la synthèse d'un brin complémentaire nouveau (fig. 10), autrement dit la réplication.
Cette règle s'applique aussi à la synthèse des autres acides nucléiques dont les nucléotides sont toujours assemblés pour constituer un brin dont l'élongation a lieu dans le sens 5′ → 3′, complémentaire d'une matrice préexistante recopiée dans le sens 3′ → 5′. Tel est le cas de la transcription, qui est la synthèse d'un brin d'ARN complémentaire au niveau d'un gène. Le brin d'ADN qui est identique à la séquence nucléotique de l'ARN est appelé brin codant ; c'est le brin opposé qui sert de matrice à l'ARN.
Le génome
Au sens strict, le génome est l'ensemble des gènes d'un organisme. Par extension, on utilise ce terme pour désigner l'ensemble des molécules portant les gènes, c'est-à-dire l'ADN. On utilise souvent, comme unité de mesure des acides nucléiques, la kilobase (ou kilopaires de bases pour l'ADN double brin). On dira donc que le génome « haploïde » (= par jeu de chromosomes) qui compte chez l'homme 3 milliards de paires de nucléotides représente 3 millions de kilopaires de bases (kpb). La plus grande partie de cet ADN ne code pour aucune séquence protéique et est constituée soit de répétitions plus ou moins monotones de nucléotides (ADN répétitif), soit de séquences uniques non codantes faisant ou non partie des gènes, comme on le verra plus loin.
Le génome bactérien est beaucoup plus petit. Chez Escherichia coli, par exemple, il est seulement d'environ 5 000 kpb. Le nombre total de gènes dans un génome donné n'est évidemment pas connu avec précision. On l'évalue, chez l'homme, à environ 30 000 à 50 000 gènes, qui occupent probablement moins du dixième du génome total. Chez les bactéries, les gènes sont beaucoup plus rapprochés et ne contiennent que des séquences codantes, ce qui rend très élevée ici la proportion d'ADN « signifiant ». Le rôle, chez les animaux et chez l'homme, des séquences non codantes d'ADN n'est toujours pas connu en détail. Elles contiennent des éléments de contrôle de la transcription des gènes, mais aussi de larges régions qui n'ont probablement aucune fonction et dont la signification précise dans l'évolution des espèces reste l'objet de spéculations. Il faut remarquer que ce n'est pas l'homme qui détient le record de la proportion d'ADN non codant : pour un nombre de gènes qui n'est probablement pas plus grand, les amphibiens ont un génome haploïde de 10 à 30 millions de kilopaires de bases ! Certains eucaryotes végétaux, la tulipe par exemple, ont également des génomes extraordinairement abondants.
Biosynthèse des protéines
À partir des gènes de procaryotes
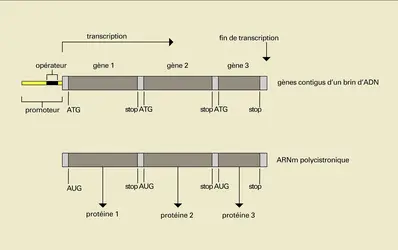
Les gènes des procaryotes, ou organismes dépourvus de noyau, ont été les premiers à être bien connus (fig. 11). La séquence d'ADN comprise entre le site d'initiation de la transcription et un signal précis de fin de transcription se retrouve intégralement dans la séquence d'ARN messager : il n'y a pas d'intron. Le plus souvent, le gène et son messager codent pour plusieurs protéines, les séquences codantes étant bordées par un triplet AUG (signal d'initiation de la traduction) et l'un des trois triplets UAA, UAG ou UGA qui sont des signaux « stop », c'est-à-dire de fin de traduction. De tels messagers sont dits polycistroniques.
Procaryotes
Encyclopædia Universalis France
Eucaryotes
Encyclopædia Universalis France
Le promoteur du gène procaryotique est le site de fixation de l'enzyme responsable de la transcription, l' ARN polymérase. L'activité de cette enzyme sur la transcription du gène est contrôlée par une séquence appelée opérateur, située de part ou d'autre du site de liaison de l'ARN polymérase. Selon les cas, l'opérateur est reconnu par une protéine se comportant comme un répresseur, ou comme un activateur.
À partir des gènes d'eucaryotes

Structure d’un gène eucaryote
Encyclopædia Universalis France
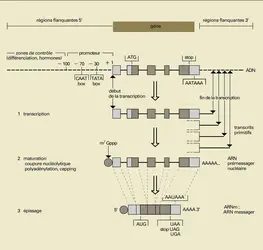
Les gènes d'eucaryotes comportent des segments, les exons, qui se retrouveront dans l'ARN messager (fig. 12), et d'autres, les introns, dont les copies seront clivées au cours de la maturation des transcrits primitifs en ARN messagers. Par définition, un gène « commence » au premier nucléotide transcrit et se termine avec le nucléotide auquel seront ajoutés, sur l'ARN, des résidus d'acide adénylique (c'est-à-dire du nucléotide dont la base est l' adénine). Contrairement à ce qui vient d'être dit à propos des gènes de procaryotes, les gènes d'eucaryotes ne contiennent pas de signal précis de fin de transcription, celle-ci cessant progressivement plus ou moins loin en aval, c'est-à-dire après le gène. En amont du gène, c'est-à-dire avant le site d' initiation de la transcription, se trouvent différents motifs de séquence qui jouent un rôle essentiel dans le contrôle de la transcription : les 50 à 70 nucléotides précédant le début du gène comportent le site de fixation de l'ARN-polymérase II (enzyme responsable de la transcription de cette classe de gènes chez les eucaryotes) et de nombreuses autres protéines (des protéines se liant directement ou indirectement à l'ADN), l'ensemble formant le complexe d'initiation de la transcription. Plus en amont et parfois fort loin (plusieurs kilobases avant le gène) se trouvent d'autres motifs d'ADN, également reconnus par des protéines, qui interviennent dans le contrôle de la transcription du gène en fonction de la différenciation tissulaire, de la modulation hormonale ou d'autres processus de contrôle. L'activation de ces éléments de séquence d'ADN implique leur liaison à des protéines et aboutit soit à une stimulation soit à une inhibition de la transcription du gène.
Les plus importantes et les mieux connues de ces séquences stimulatrices sont les enhancers dont la propriété essentielle est d'être actifs même à distance d'un gène, en amont, à l'intérieur ou en aval de lui, et indépendamment de leur orientation sur le brin d'ADN.
Outre les signaux de début et de fin de traduction, identiques à ceux des gènes de procaryotes, les gènes d'eucaryotes contiennent des éléments de séquence caractéristiques assurant un rôle de signal : pour la polyadénylation, le signal est constitué d'un motif AATAAA situé une vingtaine de bases avant le site d'addition des résidus d'acide adénylique) ; pour la formation du complexe d'initiation de la transcription au niveau du promoteur, le signal contient plusieurs types de motifs (TATA-box, CAAT-box, par exemple, ). À noter qu'il existe aussi une TATA-box dans les promoteurs procaryotiques, mais à une position légèrement différente.
Certains gènes possèdent plusieurs promoteurs, deux le plus souvent, parfois plus, dont l'utilisation est dite alternative ou optionnelle. Assez souvent, chacun des promoteurs d'un même gène est utilisé dans un contexte particulier de différenciation cellulaire ou en réponse à un type particulier de stimulation.
Les messagers transcrits sous le contrôle de ces promoteurs multiples peuvent être colinéaires, l'utilisation d'un promoteur amont aboutissant à un ARN allongé du côté 5′. Plus souvent, ils diffèrent par une région 5′ transcrite à partir d'exons différents ; dans ce cas, chaque promoteur contrôle l'initiation de la transcription au début d'exons alternatifs qui correspondent aux différentes extrémités 5′ des transcrits du gène. Ces séquences alternatives en 5′ du transcrit sont ensuite épissées, c'est-à-dire raccordées bout à bout (cf. infra, La maturation des transcrits) à des exons communs à toutes les espèces de messagers du gène. Si les exons 5′ des transcrits sont non codants, les différentes espèces de messagers seront traduites en la même protéine ; s'ils sont partiellement codants, le gène à promoteurs multiples commandera la synthèse de plusieurs protéines dont les extrémités NH2 terminales seront différentes (cf. La traduction des ARN messagers, le code génétique). Pour illustrer cette possibilité qu'a un gène d'être transcrit à partir de promoteurs optionnels, citons deux exemples. Le gène de l'aldolase A, une enzyme de la glycolyse, possède trois promoteurs commandant le début de la transcription au niveau d'exons correspondant à des séquences 5′ non codantes différentes pour chaque type de messager. L'un de ces promoteurs est actif dans tous les tissus, le second n'est exprimé que dans le muscle squelettique adulte alors que le troisième est stimulé lors de la prolifération cellulaire. Le gène d'une autre enzyme de la glycolyse, la pyruvate kinase de type L, possède deux promoteurs contrôlant l'initiation de la transcription au niveau de deux exons d'utilisation alternative correspondant à des extrémités 5′ codante et non codante différentes pour les deux types de messagers, spécifiques l'un de la différenciation hépatique et l'autre de la différenciation des érythroblastes (précurseurs des globules rouges). Dans ce cas, les molécules de pyruvate kinase L présentes dans le foie et dans les globules rouges sont différentes au niveau de leurs parties NH2 terminales codées par les exons alternatifs.
La taille des gènes est, chez les eucaryotes, extraordinairement variable, allant d'environ 1,2 kpb (1 200 paires de bases) pour un gène de globine à 2 500 kpb (2,5 millions de paires de bases) pour le gène de la dystrophine, protéine dont l'absence ou les anomalies sont responsables chez l'homme de la myopathie liée au chromosome X, ou maladie de Duchenne de Boulogne. Le rapport entre la taille des exons et des introns est également très variable, allant de valeurs supérieures à 1 (plus de séquences exoniques qu'introniques, par exemple pour le gène de l'hormone antimüllérienne) à des valeurs inférieures à 1/150 pour le gène de la dystrophine (14 kpb de séquences exoniques pour un gène de 2 500 kpb).
Cas où le produit final est un ARN
Il existe dans les cellules de nombreuses espèces d'ARN dont la fonction n'est pas de coder pour des protéines. Les ribosomes, ces particules intervenant dans la traduction des messagers, contiennent trois types d'ARN chez les procaryotes et quatre chez les eucaryotes, en interaction étroite avec des protéines. Un ribosome possède deux sous-unités. La petite sous-unité possède un ARN d'un coefficient de sédimentation 18 S (chez les eucaryotes) ou 16 S (chez les procaryotes) ; la grande sous-unité possède un ARN de 28 S (eucaryotes) ou 23 S (procaryotes) et un ARN de 5 S ; chez les eucaryotes, on trouve, de plus, une espèce de 5,8 S.
Les ARN de 18 et 28 S comme ceux de 16 et 23 S sont issus de la maturation d'un grand ARN précurseur, de 45 S chez les eucaryotes. Les gènes codant pour ces ARN sont très nombreux (plusieurs centaines chez les eucaryotes supérieurs) et sont situés les uns à la suite des autres ; cette disposition permet un couplage entre la fin de la transcription d'un gène, commandée par un signal de terminaison, et l'initiation de la transcription du gène suivant. De telles particularités assurent un niveau de synthèse très élevé des ARN ribosomaux qui représentent près de 98 p. 100 des ARN cellulaires de haut poids moléculaire. Chez les procaryotes, l'ARN ribosomal 5 S est transcrit comme une part de la même unité transcriptionnelle que les ARN 16 et 23 S alors qu'il est organisé en gènes indépendants chez les eucaryotes. Les gènes codant pour l'ARN précurseur de 45 S sont transcrits, chez les eucaryotes, par l'ARN polymérase I.
Les ARN de transfert (ARNt), l'ARN ribosomal 5 S et d'autres petits ARN nucléaires jouant un rôle dans la maturation des messagers sont également codés par de nombreux gènes réunis en groupes sur le génome et transcrits, dans les organismes eucaryotiques, par l'ARN polymérase III. Certains gènes des ARNt des eucaryotes possèdent un intron qui est excisé par une nucléase.
Modalités de l'expression génétique
La chromatine
Les brins d'ADN ne sont jamais, dans le noyau de la cellule eucaryote, sous une forme libre. Ils sont en interaction étroite avec une série de protéines, l'ensemble formant la chromatine. Les charges négatives du squelette formé par les ponts phosphodiester du double brin entraînent des interactions ioniques fortes avec des protéines basiques, les histones, elles-mêmes associées à d'autres protéines. Ces histones permettent de condenser les doubles brins d'ADN qui, s'ils étaient déroulés, mesureraient plusieurs centimètres ! La chromatine non dénaturée ressemble, en microscopie électronique, à un chapelet comportant des grains, ou nucléosomes, séparés par un lien internucléosomique. Au niveau des nucléosomes, 146 nucléotides d'ADN sont enroulés autour d'un noyau protéique octamérique composé de plusieurs types d'histones. Les liens internucléosomiques représentent une soixantaine de nucléotides d'ADN moins protégés par les histones qu'au niveau du nucléosome. La structure chromatinienne, c'est-à-dire sa condensation et la position des nucléosomes, n'est pas immuable et se modifie au cours des phénomènes d'activation transcriptionnelle des gènes. Cette modification est indispensable pour que des éléments particuliers de l'ADN, intervenant par exemple dans la constitution du complexe d'initiation de la transcription, deviennent accessibles aux protéines dont ils constituent les sites de fixation. On peut dire, très schématiquement, qu'un gène non transcrit est dans une région de chromatine dense alors qu'un gène transcrit se trouve dans une région de chromatine relâchée.
Modification des bases : méthylation
Certaines bases de l'ADN subissent une modification chimique particulière, la méthylation, qui intéresse les adénines (chez les procaryotes), et les cytosines (surtout chez les eucaryotes). Chez les eucaryotes, la méthylation affecte les doublets CG et est catalysée par des méthyltransférases encore mal connues mais dont on sait qu'elles ont une activité particulièrement forte pour un tel site hémiméthylé dans un double brin d'ADN ; la séquence :

Transcription
Transcription de l'ADN en ARN
Planeta Actimedia S.A.© Encyclopædia Universalis France pour la version française.
L'activation d'un gène d'eucaryote, c'est-à-dire le déclenchement de sa transcription, nécessite la constitution d'un complexe nucléoprotéique comportant l'ARN polymérase et de nombreuses autres protéines. Au niveau des gènes codant pour des protéines, la première étape de la constitution de ce complexe, dénommé complexe d'initiation de la transcription, est probablement la fixation sur le promoteur de protéines reconnaissant les motifs « TATA-box » ou d'autres séquences situées à proximité immédiate du site d'initiation de la transcription. Puis, correctement positionnée grâce à la mise en place préalable des facteurs précédents, l'ARN polymérase II se fixe, suivie d'autres protéines qui pourraient être requises pour l'activation de cette enzyme. Certains des partenaires du complexe d'initiation sont des protéines reconnaissant des séquences particulières d'ADN, d'autres se lient à ces protéines fixées à l'ADN plutôt qu'à l'ADN lui-même (fig. 13). La formation ou l'activation de ce complexe sont soumises à l'influence régulatrice d'autres protéines se liant soit à proximité immédiate, soit à distance sur un élément enhancer. Dans ce dernier cas (fig. 14), il semble que les deux complexes nucléoprotéiques (complexe d'initiation et complexe enhancer) puissent néanmoins interagir par contact direct, via la constitution de boucles d'ADN. Étant bien entendu que l'activité transcriptionnelle d'un gène est contrôlée par l'activité des protéines participant à la formation de complexes nucléoprotéiques, la question est celle des mécanismes du contrôle de l'activité de ces protéines. Schématiquement, deux types de phénomènes sont en cause :
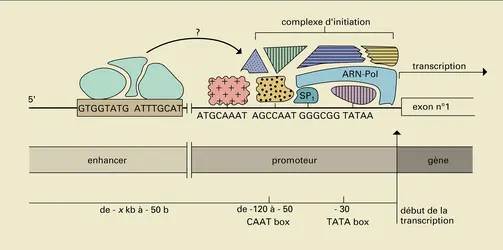
Transcription et gène enhancer
Encyclopædia Universalis France
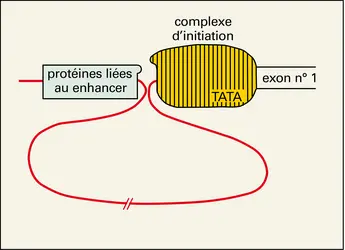
Interaction complexe enhancer-complexe d'initiation
Encyclopædia Universalis France
– L'activation post-traductionnelle de facteurs préexistants. Les protéines agissant sur la transcription sont ici préexistantes à la stimulation transcriptionnelle, mais elles sont inactives. Elles sont activées soit par la fixation d'un ligand, soit par une modification chimique, telle une réaction d'addition d'une molécule d'acide phosphorique ( phosphorylation). Les meilleurs exemples de l'activation d'un facteur transcriptionnel par la fixation d'un ligand concernent les récepteurs des hormonesstéroïdes, de la vitamine D, des hormones thyroïdiennes et de l'acide rétinoïque. En l'absence du ligand (hormone, vitamine ou acide rétinoïque), le récepteur est, dans la cellule, incapable de se fixer à l'ADN. Après fixation du ligand, le complexe récepteur-ligand se fixe à des éléments spécifiques d'ADN situés dans les régions de contrôle des gènes sensibles et en active (ou, plus rarement, en inhibe) la transcription. Le second type d'activation post-traductionnelle d'un facteur de transcription est dû à sa modification sous l'influence d'un inducteur qui peut être une hormone, un facteur de croissance ou un facteur de différenciation se liant à un récepteur de la membrane plasmique de la cellule. Cette liaison active la mise en œuvre d'un second messager (par exemple l'AMP cyclique) qui pourra lui-même stimuler une protéine kinase qui catalysera la phosphorylation du facteur transcriptionnel : cette modification pourra augmenter l'affinité de la protéine pour l'ADN, ou bien augmenter son pouvoir de stimulation (ou d'inhibition) de la transcription.
– La modification de la quantité des facteurs transcriptionnels peut également influencer la transcription des gènes.
On peut imaginer que les réponses transcriptionnelles d'une cellule stimulée d'une quelconque manière se font en cascade : les premiers événements seraient la conséquence de l'activation post-traductionnelle de facteurs préexistants, les événements suivants pouvant être dus à la modification ainsi induite du niveau d'expression de gènes codant pour d'autres types de protéines agissant sur la transcription.
Les mécanismes du contrôle transcriptionnel des gènes de procaryotes et d'eucaryotes sont de même nature, mais probablement plus complexes chez les eucaryotes que chez les procaryotes. Chez ces derniers, en effet, la transcription est contrôlée au niveau de l'initiation, de la vitesse d'élongation des transcrits et de la terminaison de la transcription. Chez les eucaryotes, le contrôle au niveau de l'initiation de la transcription est largement prédominant, nécessitant la mise en place de systèmes plus complexes que chez les procaryotes. In vivo, la vitesse de transcription équivaut à l'allongement du transcrit de 20 à 30 nucléotides par seconde. Il faut donc environ 1 minute pour transcrire un gène de globine de 1,2 kpb... et plus de 24 heures pour transcrire celui de la dystrophine de 2 500 kpb.
Rappelons aussi qu'une différence importante entre les systèmes transcriptionnels des procaryotes et des eucaryotes est l'existence chez les premiers d'une seule classe d' ARN polymérase alors que, chez les seconds, il existe des ARN polymérases différentes pour les grands ARN ribosomaux, les ARN messagers et les petits ARN.
La maturation des transcrits
C'est chez les eucaryotes que la maturation des transcrits primaires en ARN messagers qui vont franchir la membrane nucléaire et pénétrer dans le cytoplasme où ils seront traduits est le plus complexe. Les deux premières étapes de la maturation de cette copie ARN du gène que l'on appelle le transcrit primitif sont le capping et la polyadénylation qui sont deux modifications importantes pour les étapes ultérieures de maturation des ARN, leur stabilité et leur traductibilité des messagers.
Le capping consiste en la fixation au niveau du premier nucléotide transcrit d'un acide guanylique méthylé.
La polyadénylation consiste en fait en deux modifications :
– la coupure endonucléolytique éliminant toute la partie des transcrits située après le site de polyadénylation (fig. 12) ;
– l'addition au niveau de ce site de coupure d'une suite d'acide polyadénylique longue de 100 à 200 molécules.

Clivage d'un intron
Encyclopædia Universalis France
L'étape suivante dans la maturation des ARN est celle de l'excision des introns et de l' épissage entre eux des exons. Cette étape, caractéristique des eucaryotes (à de très rares exceptions près, les procaryotes n'ont pas d'introns), est complexe et exige la présence, à la limite entre les exons et les introns, de courtes portions de séquence nucléotidique très conservées ; en particulier, les introns commencent tous par les nucléotides GU et finissent par AG. Les différentes réactions aboutissant à l'épissage des exons se déroulent dans une particule nucléoprotéique appelée spliceosome. Elles peuvent être schématisées comme suit (fig. 15) :
– Le site de jonction exon- intron, en 5′ de l'intron (site donneur), est clivé, peut-être après hybridation avec un petit ARN nucléaire (ARN U1). L'extrémité 5′ libre de l'intron va dès lors se replier en lasso pour interagir avec un résidu AC situé en un site (site de branchement) localisé à quelques dizaines de bases de l'exon 3′.
– Une liaison covalente phosphodiester s'établit entre l'hydroxyle en position 2′ de l'adénosine du site de branchement et le phosphate de l'extrémité 5′ libre de l'intron, établissant la structure branchée schématisée dans le cadre de la figure, dans laquelle le lasso résulte de la formation de cette liaison inhabituelle 5′-2′.
– Le site de jonction intron-exon, en 3′ de l'intron (site accepteur), est à son tour précisément clivé, une liaison s'établissant entre l'hydroxyle libre 3′ de l'exon A et le phosphate 5′ de l'exon B. Les produits de la réaction sont l'intron avec sa structure branchée en lasso, qui sera dégradé, et les deux exons correctement liés. Le rôle général et la signification des introns ont été discutés, mais il est impératif qu'ils soient excisés de l'ARN, car ils ne peuvent pas être traduits en protéine et, s'ils étaient présents dans le messager cytoplasmique, ils introduiraient des arrêts précoces de la traduction, et donc de la synthèse des protéines. D'ailleurs, si les transcrits ont une maturation très insuffisante, ils ne peuvent passer dans le cytoplasme et sont détruits au niveau du noyau. Des mutations peuvent modifier les signaux indispensables à l'épissage, ou encore faire apparaître dans les exons ou les introns de nouveaux sites de coupure. Les conséquences de ces anomalies peuvent être une dégradation rapide de l'ARN incapable de subir sa maturation normale, ou l'arrivée dans le cytoplasme de pseudomessagers qui ne peuvent être traduits en protéines biologiquement actives.
Dans de nombreux cas, les voies d'excision-épissage sont multiples, différentes selon le tissu ou le stade de développement. Ces phénomènes d'épissages alternatifs aboutissent à ce qu'un même gène puisse avoir plusieurs messagers correspondant à des variations dans les exons en fin de compte épissés. Dans ces cas, comme dans ceux qui ont été évoqués plus haut de l'utilisation de promoteurs alternatifs, un même gène pourra donc commander la synthèse de plusieurs protéines... battant en brèche l'une des plus anciennes et fondamentales lois de la génétique moléculaire : « un gène, une protéine ».
La traduction des ARN messagers, le code génétique
La traduction d'un ARN messager en protéine débute au niveau d'un codon méthionine AUG (U = acide uridylique ; équivalent du T au niveau de l'ARN) et se termine au niveau d'un codon « stop » qui peut être UAG, UGA ou UAA. Avant et après les codons d'initiation et de fin de la traduction se trouvent les régions respectivement 5′ et 3′ non codantes du messager, auxquelles correspondent dans l'ADN des exons (ou des parties d'exons) non codants. La traduction, comme la réplication et la transcription, se fait toujours de l'extrémité 5′ vers l'extrémité 3′ des acides nucléiques. Le code génétique, c'est-à-dire la correspondance entre les nucléotides des acides nucléiques et les acides aminés des protéines, utilise des combinaisons de trois des quatre types possibles de nucléotides (ACGT dans l'ADN, ACGU dans l'ARN). Il existe 20 acides aminés et 64 combinaisons de trois lettres, appelées « codons » ou « triplets ». Nous avons vu que trois de ces combinaisons correspondent à une indication d'arrêt de traduction, les 61 autres étant « signifiantes ». La méthionine et le tryptophane ne sont codés que par un seul triplet chacun ; le codon méthionine, AUG, est également le signal d'initiation de la traduction. Les autres acides aminés sont codés par plusieurs triplets, au nombre de deux (9 fois), trois (1 fois), quatre (5 fois) ou six (3 fois). Tous les codons spécifiant le même acide aminé ont un deuxième résidu invariant. Le troisième nucléotide est en revanche variable, voire indifférent dans le cas des acides aminés codés par quatre ou six triplets (l' alanine, par exemple, peut être codée par les triplets GC-X, X étant l'un quelconque des quatre nucléotides). Le premier nucléotide est invariant, sauf dans le cas des trois acides aminés auxquels correspondent six codons, où il peut être de deux types (tabl. 2). Le code génétique est généralement qualifié d'universel (c'est-à-dire identique dans toutes les espèces), de dégénéré (ce qui indique qu'il existe plusieurs codons par acide aminé), mais non d'ambigu, puisque à un triplet donné correspond un acide aminé et un seul. Il existe en fait de très légères variations du code génétique dans les mitochondries et certains eucaryotes unicellulaires, ne remettant cependant pas fondamentalement en cause son universalité qui est à la base des possibilités du génie génétique : un gène de mammifère introduit dans une bactérie contrôlera l'expression d'une protéine ayant le même enchaînement en acides aminés que chez le mammifère de départ, à condition cependant que ce gène soit dépourvu d'introns que les procaryotes ne savent pas exciser et que son promoteur soit remplacé par un promoteur bactérien.
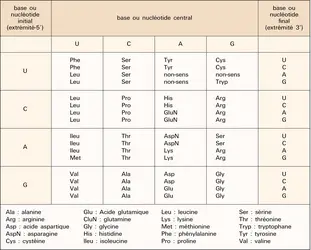
Code génétique
Encyclopædia Universalis France
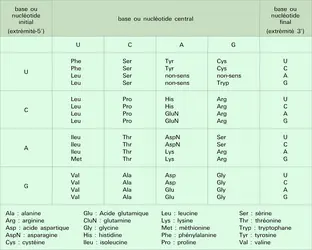
Code génétique
Encyclopædia Universalis France
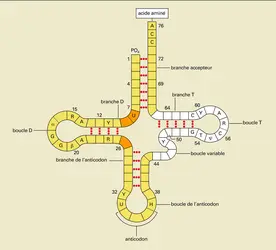
Molécule d'ARN : structure secondaire
Encyclopædia Universalis France
Il n'y a pas de complémentarité directe entre les acides aminés qui constitueront la protéine et les différents codons ; il faut, entre eux, un adaptateur qui est l'ARN de transfert, ou ARNt. Il s'agit de molécules d'ARN simple brin ayant de 73 à 93 nucléotides et adoptant une structure secondaire en trèfle extrêmement stable, due à l'appariement des différentes régions du brin d'ARN (fig. 16). Cette structure est extraordinairement conservée dans l'évolution, des micro-organismes les plus primitifs aux animaux et aux plantes. L'extrémité 3′ de la molécule est toujours ACC et constitue le site de fixation de l'acide aminé. Une boucle interne contient l' anticodon, c'est-à-dire la séquence nucléotidique complémentaire du codon de l'ARN. L'acide aminé est « chargé » sur son ARNt spécifique par l'intermédiaire d'une enzyme, l'aminoacyl-ARNt-synthétase, aboutissant à une molécule d'aminoacyl-ARNt.

Traduction ribosomale de l'ARN messager
Encyclopædia Universalis France
La traduction est un processus extrêmement complexe, encore imparfaitement connu chez les eucaryotes où il se déroule intégralement dans le cytoplasme. La première étape en est la formation (fig. 17) d'un complexe d' initiation comportant la petite sous-unité ribosomale (30 S chez les procaryotes, 40 S chez les eucaryotes) et l'aminoacyl-ARNt initiateur, c'est-à-dire celui de la méthionine (formylméthionine chez les procaryotes). Ce complexe se fixe alors à l'ARN messager, et l'anticodon du méthionyl-ARNt se positionne face au codon initiateur AUG du messager. Toutes ces étapes nécessitent la présence de nombreux facteurs d'initiation qui semblent initialement associés à la petite sous-unité ribosomale et sont libérés après la fixation au messager. La grande sous-unité ribosomale (50 S chez les procaryotes, 60 S chez les eucaryotes) se fixe alors et commence l'étape de l'élongation de la chaîne polypeptidique. Le méthionyl-ARNt est positionné au site P de la grande sous-unité ribosomale ; un aminoacyl ARNt se place en regard du codon adjacent au triplet AUG, au niveau du site A de la sous-unité ribosomale. Une liaison peptidique s'établit alors entre l'extrémité COOH terminale de la méthionine, libérée de son ARNt, et l'extrémité NH2 terminale de l'aminoacide adjacent encore fixé à son ARNt. Le ribosome se déplace ensuite d'un codon, ce qui transfère le peptidyl-ARNt formé à l'étape précédente du site A au site P du ribosome. Au niveau du site A ainsi libéré, en regard du nouveau codon adjacent en 3′ du messager, un nouvel aminoacyl ARNt va se positionner, prêt à accepter le transfert de la chaîne peptidique en cours d'élongation. Toutes ces réactions nécessitent l'apport d'énergie et la présence de différents facteurs d'élongation et d'une enzyme, la peptidyl-transférase, tous fortement liés à la particule ribosomale qui contient toute une « machinerie » complexe de synthèse protéique. Lorsque le site A du ribosome arrive au niveau d'un codon stop, la présence d'un « facteur de libération » fixé à ce codon perturbe la peptidyl-transférase qui catalyse le transfert de la chaîne peptidique sur une molécule d'eau, la libérant par conséquent et reconstituant son extrémité COOH terminale. La lecture du messager de 5′ en 3′ aura ainsi abouti à la synthèse de la protéine, de son extrémité NH2 à son extrémité COOH terminale. Les différents constituants de ces réactions sont recyclés à chaque étape (les ARNt après chaque établissement d'une liaison peptidique, les ribosomes après la rencontre d'un codon stop) et peuvent être réutilisés. Les mécanismes de contrôle de la synthèse protéique, modifiant spécifiquement la traduction de messagers particuliers en réponse à un signal, sont encore mal connus, bien qu'un tel contrôle puisse jouer un rôle non négligeable dans l'expression d'un gène. Il semble que l'étape le plus précisément modulable soit celle de l'initiation.
Synthèse des protéines membranaires et sécrétoires
Le mécanisme de passage des protéines membranaires et sécrétées au travers des membranes cellulaires est complexe. Les messagers codant pour de telles protéines sont traduits par des ribosomes liés à la membrane du réticulum endoplasmique. La partie NH2 terminale de la chaîne peptidique en voie de synthèse comporte une séquence hydrophobe particulière, dénommée par Günther Blobel (Prix Nobel de physiologie ou médecine 1999) peptide signal, qui se lie à une particule ribonucléoprotéique appelée SRP (signal recognition particle). Cette particule est reconnue par une protéine transmembranaire du réticulum endoplasmique, le récepteur du SRP. Dans ces conditions, le peptide signal traverse la membrane du réticulum et, à sa face interne, est clivé par une « signal-peptidase ». La translocation de la chaîne protéique au travers de la membrane se poursuit à mesure de sa synthèse, le phénomène étant dit cotraductionnel. D'autres modifications, telle la glycosylation, surviendront alors rapidement dans le réticulum endoplasmique et l'appareil de Golgi.
En l'absence de SRP, les protéines synthétisées restent extramembranaires. Lorsque l'ARN est traduit par un ribosome non lié à la membrane du réticulum endoplasmique, la fixation sur le peptide signal d'un SRP libre bloque la poursuite de la traduction ; celle-ci reprendra lorsque le système sera à nouveau au contact de membranes et que le SRP sera fixé à son récepteur. Il s'agit là d'un possible mécanisme de régulation de la synthèse des protéines sécrétoires en fonction de l'état physiologique de la cellule. La particule SRP est constituée d'un ARN d'environ 300 bases, l'ARN 7 SL. La séquence de cet ARN montre qu'une partie en est homologue d'une séquence hautement répétée dans le génome, la séquence « Alu ». Il semble d'ailleurs que les séquences Alu qui sont dispersées dans tout l'ADN nucléaire des mammifères, notamment de l'homme, soient des pseudogènes du type des rétrogènes (c'est-à-dire des ADN complémentaires d'ARN, synthétisés sous l'action d'une transcriptase reverse, qui se réintègrent au hasard dans l'ADN chromosomique), dérivés à l'origine de cet ARN 7 SL. L'autre partie de l'ARN 7 SL est spécifique de la particule SRP, aucun équivalent n'en étant retrouvé ailleurs. La particule SRP possède aussi 6 protéines, étroitement intriquées à l'ARN.
Plasticité du génome
Séquences répétitives
Les séquences Alu, dont nous venons de voir l'homologie avec l'ARN 7 SL de la particule SRP, sont extrêmement nombreuses, dispersées dans le génome qui en contient 300 000 copies par jeu de chromosomes. D'autres séquences de même type existent, par exemple les séquences ID du rat, qui ressemblent à des « rétrogènes » dérivés d'ARNt, ou les éléments B1 et B2 de la souris. Beaucoup de ces éléments génétiques répétés sont transcrits soit de façon autonome par l' ARN polymérase III, soit comme une partie d'unités de transcription de l'ARN polymérase II. La fonction de ces séquences est encore assez mystérieuse. Augmentant la fréquence des phénomènes de recombinaison homologue (cf. infra), elles pourraient faciliter la plasticité du génome au cours de l' évolution. L'abondance des transcrits de certaines séquences répétitives varie en fonction du développement embryonnaire, de la différenciation tissulaire et de la prolifération cellulaire, ce qui suggère que ces transcrits pourraient avoir un rôle dans ces phénomènes.
Gènes, pseudogènes et familles multigéniques
Duplications géniques et dérive génétiqueProblème sur une balise : med -
<med id="V100216B" type="FIG"/>
Si le problème persiste, n'hésitez pas à contacter le service client Universalis, en précisant bien l'adresse URL de la page.
Problème sur une balise : med -
<med id="V100216B" type="FIG"/>
Si le problème persiste, n'hésitez pas à contacter le service client Universalis, en précisant bien l'adresse URL de la page.
Au cours de l'évolution surviennent des phénomènes de duplication de gènes préexistants (fig. 18), aboutissant à de nouvelles copies dont le destin est variable. Parfois, la nouvelle copie reste active et code pour le même message que le gène initial ; des différences entre les deux gènes s'accumulent cependant dans les régions non codantes, introns et portions non codantes des exons. Ce modèle s'applique parfaitement aux deux gènes de la chaîne α de l'hémoglobine. Dans d'autres cas, les gènes dupliqués vont, tout en restant actifs, évoluer pour leur propre compte, aboutissant à la synthèse de protéines fonctionnellement différentes et parfois contrôlées différemment au cours du développement et de la différenciation. Ainsi en est-il probablement des isoenzymes, de l'albumine et de l'α-foetoprotéine ou des chaînes β, γ et δ de l' hémoglobine. Souvent, enfin, les nouvelles copies de gènes vont être rapidement modifiées dans leurs séquences codantes et régions de contrôle, ce qui aboutit à des pseudogènes non fonctionnels (non transcrits) dans lesquels, en l'absence de la pression sélective qui tend à éliminer d'un gène les mutations risquant d'en altérer la fonction, les modifications de séquence vont s'accumuler au cours de l'évolution. Certains de ces pseudogènes inactifs pourraient représenter de véritables « laboratoires » où se prépare l'acquisition d'une fonction nouvelle, le pseudogène précédant ici le gène actif et pouvant jouer un rôle essentiel dans l'évolution des espèces.
Rétrogènes (« processed genes »)
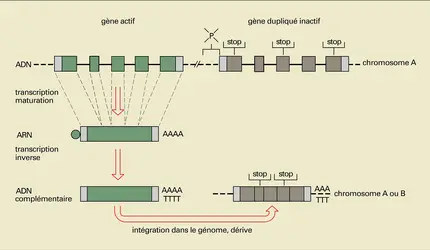
Pseudogènes : formation
Encyclopædia Universalis France
Certains pseudogènes (fig. 18) semblent être des copies ADN d'ARN messagers ayant subi une maturation normale. De telles copies se réintégreraient au hasard dans le génome, donnant des pseudogènes caractérisés par l'absence de promoteur et d'introns, et par la présence d'une extension d'acide polyadénylique.
La signification et le mécanisme de formation de ces séquences restent parfaitement énigmatiques.
Familles multigéniques, recombinaisons génétiques et évolution
Les familles multigéniques sont composées d'un nombre pouvant varier de quelques unités à quelques centaines de gènes et pseudogènes partiellement homologues, localisés en une même région chromosomique ou dispersés sur tous les chromosomes. Dans le cas d'une famille multigénique « géographiquement » localisée, des appariements entre des séquences partiellement homologues non alléliques (c'est-à-dire ne correspondant pas aux deux gènes parentaux d'un même locus) aboutissent à des échanges d'information génétique, responsables d'une évolution concertée d'un groupe de gènes qui, en l'absence de ces échanges, divergeraient rapidement (cas par exemple des gènes du complexe majeur d'histocompatibilité, ou des régions variables des immunoglobulines). Ce phénomène est dénommé « conversion génique » ; son mécanisme reste controversé.
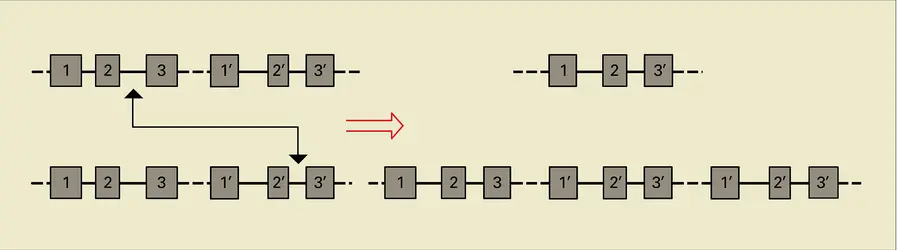
Crossing over entre deux gènes non alléliques
Encyclopædia Universalis France
Par ailleurs, ces réitérations de gènes partiellement homologues en une même zone du chromosome favorisent les échanges non équationnels entre chromatides lors de la méiose, ou crossing over, à l'origine de délétions géniques particulièrement bien illustrées dans de nombreux types de thalassémies (fig. 19).
Réarrangements géniques et différenciation
Nous venons de voir que, au cours de l'évolution, le génome n'était pas immuable, ses recombinaisons constituant même l'un des moteurs de cette évolution. Des remaniements surviennent aussi chez les animaux supérieurs, notamment chez les mammifères, lors de certains processus de différenciation des cellules du système immunitaire. Les quatre gènes codant pour les deux chaînes des deux types de récepteur pour l'antigène des cellules T (αβ et γδ) subissent un réarrangement lors de la différenciation des lymphocytes T ; de même, les gènes des chaînes légères λ et κ et des chaînes lourdes d'immunoglobulines sont réarrangés lors de la différenciation des lymphocytes B. Dans les deux cas, le réarrangement aboutit à la combinaison variable de différents segments génétiques codant, ensemble, pour les régions variables du récepteur T ou des molécules d'anticorps, et à leur rapprochement du segment génétique codant pour la partie constante de ces molécules. Ces travaux, qui ont valu en 1987 le prix Nobel de médecine à Susumu Tonegawa, expliquent comment peuvent être synthétisées des molécules-anticorps ou récepteurs T qui comportent une partie hautement variable spécifique de centaines de milliers d'antigènes possibles, et une partie constante codée par un seul gène ou un petit nombre de gènes.
Méthodologie des recombinants d'ADN
Il s'agit de l'ensemble des techniques utilisant la recombinaison de fragments d'ADN, c'est-à-dire la liaison entre eux de fragments d'origines différentes.
Le clonage d'ADN
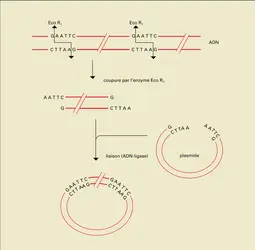
ADN : enzymes de restriction, coupures et liaisons
Encyclopædia Universalis France
Les trois techniques qui ont autorisé l'avènement du génie génétique sont l' hybridation moléculaire, la coupure de l'ADN par les enzymes de restriction et le clonage moléculaire. Auparavant, en effet, il n'était pas possible d'isoler un gène donné, car il ne représentait qu'une infime partie de l'ADN cellulaire total dont on pouvait disposer. Si on imagine par exemple qu'un gène moyen mesure 10 kb, cela ne correspond qu'au 1/300 000 de la taille totale d'un génome haploïde humain et il n'est absolument pas possible, d'une part, de reconnaître ce gène au milieu des autres fragments d'ADN, d'autre part, quand bien même cela l'eût été, d'en disposer d'une quantité suffisante pour pouvoir l'étudier. Les trois techniques citées plus haut permettent de surmonter ces difficultés. Les enzymes de restriction (fig. 20) reconnaissent des séquences bien particulières de nucléotides au niveau desquelles elles clivent l'ADN double brin, produisant des fragments de tailles variables. Le clonage moléculaire d'ADN consiste à produire des clones bactériens dont chacun contient un fragment de l'ADN qu'on désire isoler. Pour parvenir à ce résultat, des fragments d'ADN produits par le clivage à l'aide d'enzymes de restriction sont insérés au hasard dans des « vecteurs », c'est-à-dire des éléments génétiques capables d'être transférés dans des bactéries et de s'y multiplier (fig. 21). Ces vecteurs ont eux-mêmes été « préparés » par des clivages à l'aide d'enzymes de restriction produisant des extrémités d'ADN qu'on peut lier (à l'aide d'une enzyme appelée ligase) aux fragments de l'ADN à cloner. Les vecteurs « recombinés » par l'insertion d'ADN à cloner sont alors transférés dans des bactéries. Chacune d'entre elles ne pouvant être « transformée » que par un seul vecteur, toutes les bactéries dérivées d'une bactérie transformée, formant une colonie (ou clone), contiendront le même fragment d'ADN étranger qui sera, à ce niveau, considérablement amplifié. Il ne reste plus alors qu'à reconnaître, parmi les centaines de milliers ou les millions de clones obtenus, lequel ou lesquels contiennent le fragment d'ADN recherché : c'est l'étape de « criblage » de la « banque » d'ADN dont le principe est l'hybridation spécifique entre un fragment radioactif d'ADN dénommé « sonde » qu'on possède, et l'ADN des colonies bactériennes (fig. 21 et 22). Les deux brins d'ADN sont normalement associés grâce à la complémentarité de couples de nucléotides : A-T (ou A-U si l'hybridation se fait avec de l'ARN), et C-G. Si on dissocie un ADN double brin, chacun des brins séparés pourra alors s'apparier spécifiquement avec une séquence « complémentaire » qui, si elle est radioactive, permettra sans ambiguïté de détecter une séquence donnée au milieu d'autres séquences. De cette manière, il est possible de repérer la (ou les) colonie(s) contenant un fragment d'ADN complémentaire de la sonde utilisée (fig. 22).

Clonage d'ADN
Encyclopædia Universalis France
Hybridation moléculaire
Encyclopædia Universalis France
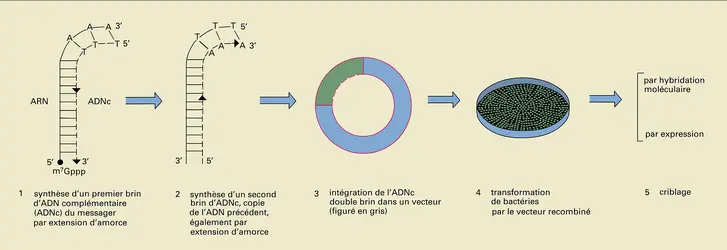
ADN : confection de banques complémentaires
Encyclopædia Universalis France
Dans l'exemple illustré par la figure 21, des fragments d'ADN d'environ 15 à 20 kilopaires de bases sont insérés dans un vecteur qui est un phage, c'est-à-dire un virus de bactérie. L'immensité des distances sur le génome humain... et l'immensité de certains gènes (environ 200 kilopaires de bases pour le gène du facteur antihémophilique A, 10 fois plus pour celui de la dystrophine) font cependant parfois désirer cloner de plus grands fragments. Les cosmides sont des vecteurs de type plasmidique (fig. 23) dans lesquels ont été ajoutées les extrémités cos de l'ADN du phage λ, extrémités qui permettent l'empaquetage dans la capside du phage λ. Cette capside accepte 50 kilopaires de bases ; si le cosmide a une taille de 5 kilopaires de bases, il y a donc la place pour un fragment d'ADN étranger de 45 kilopaires de bases. La capside permet une transformation bactérienne (c'est-à-dire un transfert de l'ADN à l'intérieur des bactéries) très efficace ; le cosmide se comporte ensuite comme un plasmide.
Une méthode plus récente permet de cloner des fragments d'ADN de plusieurs centaines de kilopaires de bases dans la levure. Ces fragments sont insérés dans un vecteur qui comprend des séquences de centromère et de télomère de levure ; après introduction dans les levures, ils se comportent comme des chromosomes artificiels ( YAC) de ces micro-organismes.
Le clonage d'ARN : les banques d'ADN complémentaire
Il est souvent très intéressant de cloner non pas un gène, mais un messager, ou, plus exactement, un ADN complémentaire (ADNc) du messager. Les processus de différenciation font, en effet, que seuls certains gènes sont exprimés dans chaque type de tissu ; par exemple, les gènes de globine ne sont actifs que dans les précurseurs des globules rouges. Le gène de la β globine représente moins du millionième de l'ADN cellulaire mais, dans les réticulocytes, l' ARN messager correspondant représentera de 30 à 40 p. 100 de tous les messagers. Il est donc ici bien plus facile d'isoler l'ARN messager que le gène ! Par ailleurs, l'un des buts du génie génétique est de faire produire par des micro-organismes, souvent des bactéries, des protéines normalement synthétisées par des organismes eucaryotes. Or les procaryotes sont incapables d'exciser les introns et donc d'exprimer en protéine un gène eucaryotique complet, si bien que c'est le plus souvent un ADN complémentaire, dépourvu d'introns puisqu'il est une copie de l'ARN messager, qui est utilisé. La figure résume le principe de la constitution d'une « banque » d'ADN complémentaire. La première étape consiste à recopier l'ARN en un brin d'ADN complémentaire, puis à transformer cet ADNc monobrin en une forme double brin qui est ensuite clonée selon le même principe qu'un fragment d'ADN génomique.

Xénope du Cap
T. Vinckers
Les clones contenant la séquence recherchée sont détectés soit par hybridation moléculaire, soit par expression de la séquence clonée en protéine synthétisée par les cellules du clone, comme indiqué sur la figure. Cette protéine peut être reconnue spécifiquement par des anticorps ; elle peut aussi être identifiée grâce à ses propriétés biologiques. Par exemple, il est possible maintenant d'isoler un ADNc correspondant à un récepteur membranaire dont on ne connaît pas la structure et contre lequel on n'a pas d'anticorps. Les molécules d'ADNc d'un groupe de clones sont converties par transcription in vitro en molécules d'ARN messager qui sont injectées dans des cellules spéciales dépourvues du récepteur étudié, souvent des œufs de batracien (habituellement le xénope). Si le récepteur étudié est celui de la sérotonine (ou de toute autre hormone ou substance active) et si parmi les ARN injectés dans les œufs de xénope figurait celui codant pour le récepteur, les cellules injectées deviendront sensibles à la sérotonine, qui créera par exemple une modification du potentiel de membrane. Il ne restera plus alors qu'à subdiviser le groupe de clones positif en ses constituants testés selon le même principe pour identifier celui contenant l'ADNc recherché.
Analyse des acides nucléiques
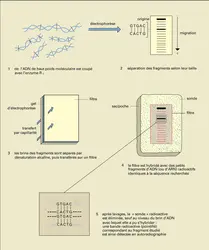
Séparation électrophorétique, Southern et Northern blots
Une première question qui se pose lorsqu'on analyse un gène et son messager est celle de leur présence... et de leur quantité. La figure 24 montre comment il est possible de détecter, parmi les millions de fragments engendrés par la coupure d'ADN cellulaire à l'aide d'une enzyme de restriction, celui ou ceux contenant la séquence nucléotidique recherchée. Les fragments d'ADN sont séparés selon leur taille par électrophorèse, c'est-à-dire par migration dans un champ électrique au travers d'un gel jouant un rôle de tamis moléculaire. Une autre technique, consistant à modifier selon une périodicité particulière la direction du champ électrique (méthode dite de l'électrophorèse en champ pulsé), permet de séparer de très grands fragments, de plus de 1 000 kilopaires de bases, ce qui est particulièrement intéressant pour établir une carte physique de grands génomes, tel celui de l'homme. En fonction du même principe de séparation électrophorétique selon la taille, transfert sur filtre et hybridation moléculaire, que pour l'ADN, les ARN cellulaires peuvent être analysés et une espèce particulière peut être détectée. La méthode de séparation transfert-hybridation des fragments d'ADN a été décrite en 1976 par E. M. Southern et est donc appelée couramment Southern blot, qui pourrait se traduire par « buvardage selon Southern ». Par jeu, la méthode équivalente concernant l'ARN fut dénommée Northern blot.
Détermination de la séquence nucléotidique de l'ADN
Il est extrêmement aisé de déterminer l'enchaînement des nucléotides constituant un brin d'ADN. Deux techniques – dont les descriptions valurent le prix Nobel à leurs auteurs – sont couramment utilisées. La méthode de Maxam et Gilbert fait appel à des réactions chimiques clivant l'ADN au niveau de bases particulières. La méthode de Sanger est quant à elle fondée sur l'arrêt de l'allongement d'un brin d'ADN catalysé par une ADN polymérase lorsque le dernier nucléotide incorporé est un dérivé ayant perdu ses radicaux hydroxyles en 2′ et 3′ (di-désoxynucléotide). Dans les deux cas, les réactions sont conduites dans des conditions telles qu'il n'y ait qu'une coupure ou qu'un arrêt, situés au hasard, par fragment étudié. En effectuant quatre réactions séparées, chacune coupant l'ADN ou stoppant son allongement au niveau de l'un des quatre nucléotides A, C, G, T, on va ainsi engendrer toute une série de sous-fragments se terminant au niveau de l'un quelconque des nucléotides du fragment analysé. Ces sous-fragments sont marqués par un isotope radioactif au niveau d'une de leurs extrémités, puis sont séparés selon leur taille par électrophorèse (fig. 24). Les échantillons correspondant à chacune des réactions spécifiques des A, des C, des G ou des T sont déposés séparément. L'autoradiographie du gel de séquence a l'aspect d'une succession de traits (chacun correspondant à un sous-fragment radioactif), les fragments engendrés par les quatre réactions s'échelonnant au niveau du gel dans l'ordre (de taille décroissante) suivant : deux fragments dans la bande des A, puis un dans la bande des G, trois dans la bande des C, un dans la bande des T... L'enchaînement des nucléotides sera, en partant du côté opposé au marquage : A, A, G, C, C, C, T....

Frederick Sanger
Keystone/ Hulton Archive/ Getty Images
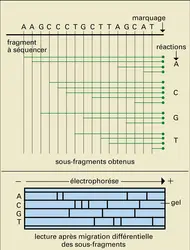
Détermination de la séquence nucléotidique de l'ADN
Encyclopædia Universalis France
Génie génétique et médecine
Les buts de l'application à la médecine du génie génétique peuvent être résumés en quatre mots : connaître, dépister, produire et guérir.
Connaître la structure d'un gène, ou d'un messager, permet de déduire la séquence en acides aminés de la protéine pour laquelle ils codent, d'en prévoir souvent la fonction et d'étudier sa localisation. Il faut savoir, en effet, qu'il est maintenant toujours possible d'isoler un gène codant pour une protéine contre laquelle on a... au moins des anticorps, et de plus en plus souvent réalisable d'accéder à un gène connu simplement pour être modifié dans des maladies dont on ne connaît pas même le mécanisme (exemples de la myopathie de Duchenne de Boulogne ou de la fibrose kystique du pancréas). Les techniques de détermination de la séquence nucléotidique, en perfectionnement permanent, sont sans aucune commune mesure plus aisées et rapides que les techniques d'analyse de la séquence en acides aminés, si bien que la voie royale pour élucider la structure d'une protéine est maintenant de cloner et de séquencer son gène. Enfin, la possession de sondes spécifiques d'un gène donne la possibilité d'analyser en détail les mécanismes du contrôle de son expression.
Dépister des maladies héréditaires par l'analyse de l'ADN de cellules embryonnaires permet de plus en plus souvent de parvenir à des diagnostics prénataux. Le dépistage des modifications des oncogènes dans des cancers ou des maladies précancéreuses doit prendre une place croissante en médecine. Les méthodes d'hybridation moléculaire permettent enfin de détecter avec fidélité et sensibilité la présence de génomes viraux dans des tissus humains.
Produire des protéines d'intérêt biologique (hormones polypeptidiques, facteurs de coagulation, facteurs de croissance, etc.) ou des antigènes vaccinaux n'est souvent possible que grâce aux méthodes du génie génétique qui sont donc appelées à changer totalement les perspectives thérapeutiques dans tous ces cas.
Guérir des maladies héréditaires par transfert de matériel génétique n'est plus maintenant un rêve de science-fiction mais a déjà été réalisé dans plusieurs modèles animaux et constitue la première arme thérapeutique contre les maladies génétiques humaines.
Au reste, les retombées et les applications du génie génétique dépassent de loin, en fait, les limites de la médecine.
Le transfert de gènes dans les plantes a débuté depuis plusieurs décennies et est en expansion rapide. Les buts immédiatement poursuivis sont de conférer aux plantes une résistance aux herbicides, voire aux insectes, aux parasites, aux bactéries ou aux virus (cf. O.G.M.).
D'autres recherches concernent la protection contre le gel, les vaccinations et l'amélioration des espèces animales.
Accédez à l'intégralité de nos articles
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Axel KAHN : président de la Commission du génie biomoléculaire, directeur de recherche à l'I.N.S.E.R.M.
- Philippe L'HÉRITIER : professeur honoraire à la faculté des sciences de Clermont-Ferrand
- Marguerite PICARD : professeur à l'université de Paris-Sud, Orsay
Classification
Médias

Gregor Johann Mendel
Hulton Archive/ Getty Images

ADN
Planeta Actimedia S.A.© Encyclopædia Universalis France pour la version française.
Génétique : monohybridisme
Encyclopædia Universalis France
Autres références
-
CHROMOSOMES ET GÉNÉTIQUE
- Écrit par Nicolas CHEVASSUS-au-LOUIS
- 194 mots
Pour étudier les mécanismes de l'hérédité, le généticien américain Thomas H. Morgan (1866-1945) choisit de travailler sur la mouche du vinaigre (drosophile). Alors que la drosophile possède normalement des yeux rouges, Morgan remarque certains individus aux yeux blancs. Ce caractère...
-
GÉNÉTIQUE ET DÉVELOPPEMENT PSYCHOLOGIQUE
- Écrit par Michèle CARLIER
- 2 172 mots
Quiconque observe des êtres humains est frappé par leurs points communs et leurs différences. Points communs et différences trouvent d’abord leur origine dans la génétique. Considérons deux espèces très proches : le Pan troglodytes (chimpanzé) et l’Homo sapiens (notre espèce). Leurs...
-
AGRESSIVITÉ, éthologie
- Écrit par Philippe ROPARTZ
- 3 932 mots
Il existe essentiellement deux méthodes pour tester l'intervention d'éventuels facteurs génétiques dans le déterminisme des comportements d'agression chez l'animal ; tout d'abord, on dispose aujourd'hui de plusieurs dizaines de lignées ou souches de souris consanguines entre lesquelles des comparaisons... -
ALCAPTONURIE
- Écrit par Jacques HANOUNE
- 383 mots
Depuis 1822, on connaît l'alcaptonurie, une maladie très rare apparaissant dans l'enfance, associant une modification de la couleur de la peau, la présence d'urines foncées et une atteinte articulaire. En 1898, le médecin britannique Archibald Garrod identifiait la substance responsable...
-
ANIMAUX MODES DE REPRODUCTION DES
- Écrit par Catherine ZILLER
- 4 448 mots
- 4 médias
 ...Souvent, les individus fils restent rattachés à l'animal souche : la reproduction asexuée produit alors une colonie (Cœlentérés, Bryozoaires, Tuniciers). Ce type de reproduction repose sur la seule division mitotique, au cours de laquelle le nombre de chromosomes reste constant, de sorte que le patrimoine...
...Souvent, les individus fils restent rattachés à l'animal souche : la reproduction asexuée produit alors une colonie (Cœlentérés, Bryozoaires, Tuniciers). Ce type de reproduction repose sur la seule division mitotique, au cours de laquelle le nombre de chromosomes reste constant, de sorte que le patrimoine... -
ANIMAUX MODÈLES, biologie
- Écrit par Gabriel GACHELIN et Emmanuelle SIDOT
- 9 550 mots
- 8 médias
 ...glissement d'un très petit nombre d'espèces animales vers un statut plus particulier d'animal modèle défini comme tel est associé à – sinon provoqué par – une approche de plus en plus génétique de la biologie et de la médecine, qui va surtout s'affirmer au cours du dernier tiers du xxe siècle avec...
...glissement d'un très petit nombre d'espèces animales vers un statut plus particulier d'animal modèle défini comme tel est associé à – sinon provoqué par – une approche de plus en plus génétique de la biologie et de la médecine, qui va surtout s'affirmer au cours du dernier tiers du xxe siècle avec... - Afficher les 132 références
Voir aussi
- POLYPEPTIDES
- ENZYMES
- ADN RÉPÉTITIF
- FAMILLE MULTIGÉNIQUE
- MATURATION DE L'ARN
- PROMOTEUR, biologie moléculaire
- CARTE GÉNÉTIQUE
- CHROMOSOMES ARTIFICIELS DE LEVURE ou YAC
- LOCUS, génétique
- HYBRIDATION MOLÉCULAIRE
- ALTERNANCE DE PHASES
- HÉRÉDITAIRES MALADIES ou MALADIES GÉNÉTIQUES
- CYTOPLASME
- RÉTICULUM ENDOPLASMIQUE
- NUCLÉOTIDES
- GÉNOTYPE
- CAPSULE BACTÉRIENNE
- DUPLICATION, biologie moléculaire
- CODON, biologie moléculaire
- ARN DE TRANSFERT ou ARNt
- ARN MESSAGER ou ARNm
- ARN POLYMÉRASE
- CYTOSINE
- ADÉNINE
- RÉPRESSEUR, biologie moléculaire
- RÉPLICATION, biologie moléculaire
- OPÉRON
- TRANSCRIPTION, biologie moléculaire
- TRADUCTION, biologie moléculaire
- AUXOTROPHES
- HAPLOÏDIE
- EUCARYOTES
- SCIENCES HISTOIRE DES, XXe XXIe s.
- GÉNÉTIQUE VÉGÉTALE
- PHOSPHORIQUES ACIDES
- TRAFIC INTRACELLULAIRE
- SÉQUENÇAGE, génétique moléculaire
- PEPTIDE SIGNAL, cytologie
- COSMIDE
- SONDES RADIOACTIVES, biologie moléculaire
- ADN RECOMBINANT
- ALANINE
- POLYPEPTIDIQUE CHAÎNE
- PHOSPHORYLATION
- MÉTHIONINE
- PHOSPHATES
- PROTÉINES MEMBRANAIRES
- MARQUAGE ISOTOPIQUE
- GÉNOME
- BIOLOGIE MOLÉCULAIRE
- DIPLOÏDIE
- AUTOFÉCONDATION
- ÉPISSAGE ALTERNATIF ou ÉPISSAGE DIFFÉRENTIEL, génétique moléculaire
- CHIASMA, cytologie
- CROSSING-OVER, génétique
- CHROMOSOMES
- CHROMATIDES
- PROCARYOTES ou PROTOCARYOTES
- PROTÉINES BIOSYNTHÈSE DES
- INFORMATION GÉNÉTIQUE
- CAPSIDE
- CLONE
- ALLÈLE
- HOMOZYGOTE
- HÉTÉROZYGOTE
- DOMINANCE, génétique
- ASCOBOLUS
- ALLÉLISME TEST D'
- CISTRON
- TRYPTOPHANE
- VIRALE PARTICULE ou VIRION
- RECOMBINAISON GÉNÉTIQUE
- RÉCESSIVITÉ, génétique
- TRANSFORMATION BACTÉRIENNE
- POPULATIONS GÉNÉTIQUE DES
- CONVERSION, biologie moléculaire
- BARRIÈRE, génétique
- ADAPTATION BIOLOGIQUE
- CYTOGÉNÉTIQUE
- ENZYMES DE RESTRICTION ou ENDONUCLÉASES DE RESTRICTION
- RÉGULATION GÉNÉTIQUE
- CLONAGE MOLÉCULAIRE
- EXPRESSION GÉNÉTIQUE
- EXON
- INTRON
- INITIATION, biologie moléculaire
- NUCLÉOSOME
- MESSAGER, biochimie
- NUCLÉOTIDIQUE SÉQUENCE
- GÉNÉTIQUE MOLÉCULAIRE
- DUCHENNE MYOPATHIE DE
- SÉGRÉGATION, génétique
- MACROMOLÉCULES BIOLOGIQUES
- ANTICODON, génétique moléculaire
- DISJONCTION GÉNIQUE
- ISOTOPES, biologie
- SECOND MESSAGER, biologie
- GÉNIE BIOMÉDICAL ET BIO-INGÉNIERIE
- RÉCEPTEURS MEMBRANAIRES
- DYSTROPHINE
- LYMPHOCYTES B
- LYMPHOCYTES T
- ADN COMPLÉMENTAIRE ou ADNc
- PEPTIDIQUE CHAÎNE
- ÉPISSAGE, génétique moléculaire
- RÉARRANGEMENT GÉNIQUE
- MÉTHYLATION, biologie moléculaire
- TRANSCRIT, génétique moléculaire
- PSEUDOGÈNES
- RÉTROGÈNES
- PYRUVATE KINASE
- RÉCEPTEUR, biochimie
- PEPTIDYL TRANSFÉRASE
- ENHANCER
- BIOLOGIE HISTOIRE DE LA
- BASES NUCLÉIQUES ou BASES AZOTÉES
- CARACTÈRES ACQUIS, biologie
