MOTEURS DE RECHERCHE
Article modifié le
Un moteur de recherche est une application informatique qui permet de retrouver, dans un ordinateur personnel ou sur le Web (World Wide Web), des documents (textes, images, vidéos…) apportant des renseignements susceptibles de répondre à une requête formulée généralement à l’aide de mots-clés. Les moteurs commerciaux du Web ont connu rapidement le succès en généralisant la gratuité de leur utilisation en échange de l’affichage de publicités.

Infrastructure matérielle des moteurs de recherche
wavebreakmedia/ Shutterstock

En effet, l'invention du Web, dispositif de publication de documents permettant leur consultation via Internet, a rapidement généré une masse considérable d’informations. Pour recenser les documents ainsi publiés, ce sont d'abord des répertoires de sites qui ont été élaborés. Ces premiers annuaires inventoriaient les sites Web en y associant une courte description et les classaient par catégories de sujets, ce qui requérait un traitement manuel. Face à la multiplication des publications en ligne, ce procédé a rapidement atteint ses limites. Les moteurs de recherche, en automatisant le repérage de l'information, se sont peu à peu rendus indispensables. À partir de quelques mots-clés, ils permettent de découvrir des ressources ou de trouver des informations sur toutes sortes de sujets. Leurs performances ne cessent de progresser : ils traitent désormais des milliards de documents, leur ergonomie et leur simplicité d'utilisation les mettent à la portée de tous. Les moteurs les plus connus sont des moteurs commerciaux (Google, Bing de Microsoft, Yahoo!, Baidu en Chine ou encore Yandex en Russie) qui tirent leurs revenus de la publicité. Ces services suscitent régulièrement des controverses liées aux enjeux économiques et culturels mais aussi politiques et éthiques qu'ils recouvrent.
Fonctionnement des moteurs de recherche Web
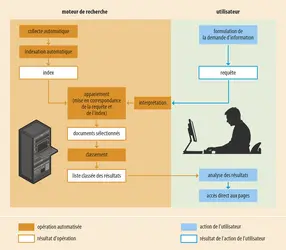
Fonctionnement d'un moteur de recherche
Encyclopædia Universalis France
Alors qu'un navigateur Web permet de consulter un site ou une page dont on connaît l'adresse sur Internet, un moteur de recherche est conçu pour faire une recherche à partir de quelques mots clés et obtenir, en résultats, une liste de liens vers des documents susceptibles d'être pertinents. Si, depuis la fin des années 1990, les moteurs se sont diversifiés quant à la nature des documents qu'ils permettent de retrouver (pages Web, images, vidéos, fichiers son), leur principe général de fonctionnement reste globalement toujours le même.
Un moteur de recherche repère les pages Web et les caractérise par des descriptions, le tout de manière entièrement automatique. Plutôt que de naviguer dans les catégories prédéfinies d'un annuaire, l'internaute formule une requête dans une barre de recherche à partir de mots clés. La qualité globale d'un moteur de recherche dépend de ses fonctions de collecte, d'indexation et de classement des documents, ainsi que de son interface d'interrogation.
Le repérage et la collecte des pages Web
La collecte des pages repose sur le principe du Web qui associe à chaque document publié une adresse URL (uniform resource locator). Elle est réalisée par un « robot », un programme informatique (appelé spider ou crawler en anglais) qui, à partir d'une liste initiale d'adresses, visite les pages Web correspondantes et y collecte les adresses mentionnées dans les liens. De proche en proche, cette technique permet de découvrir de nouvelles ressources en ligne. Le procédé détaillé de la collecte des adresses diffère d'un moteur à l'autre, selon l'ensemble d'adresses de départ qui sert à l'initier, les techniques de suivi des liens et la fréquence de mise à jour de la base d'adresses du moteur. C'est pourquoi les différents moteurs de recherche n'ont pas la même portée et ne couvrent pas les mêmes ressources. Les moteurs copient sur leurs propres serveurs (cache) les pages rencontrées afin de disposer d'une version stabilisée pour l'indexer.
Indexation des documents
Les pages Web collectées sont analysées par un logiciel qui procède à leur indexation. L'indexation consiste à caractériser les pages par des mots clés pour permettre de les retrouver. Dans le cas des moteurs de recherche, l'extraction de mots ou de groupes de mots à partir des documents est automatisée. Le moteur constitue un index qui, pour chaque mot repéré, renvoie aux pages où ce mot est présent. Pour un programme informatique, un mot est une simple suite de caractères entre deux séparateurs (par exemple une espace ou un signe de ponctuation), il n'a pas de sens. L'indexation du texte intégral pose des problèmes liés à l'homonymie (un mot peut avoir des sens très différents, par exemple « paris » peut correspondre aux enjeux des joueurs, à la capitale de la France ou au personnage de la mythologie grecque) et à la synonymie (une page comportant le mot « voiture » et une autre le mot « automobile » ne seront pas liées dans l'index). C’est pourquoi des techniques d’apprentissage profond ont été implémentées pour tenir davantage compte du contexte linguistique.
Certains moteurs, comme Google, ajoutent à l'index d'une page, sous certaines conditions, les mots qui apparaissent dans les liens pointant vers elle. Le procédé permet d'obtenir d'autres termes descripteurs jugés représentatifs par ceux qui ont signalé la page dans leur propre site.
Le classement des résultats
De nombreuses études scientifiques montrent que les utilisateurs de moteurs emploient peu de mots dans leurs requêtes (à peine plus de deux mots en moyenne), et ils ne consultent souvent que les tout premiers liens proposés dans les résultats alors qu'il existe plusieurs centaines de milliers voire millions de pages candidates. Le défi auquel sont confrontés les moteurs de recherche est non seulement de retrouver les pages qui peuvent correspondre à la demande formulée mais surtout de classer les résultats par pertinence. Pour ce faire, chaque moteur a sa propre recette qui mélange un grand nombre de critères exprimés dans des algorithmes. L'importance d'un mot pour décrire une page peut être déterminée à partir de sa position dans la page (par exemple, un mot présent dans le titre de la page aura plus de poids que les autres) ou sa fréquence d'apparition. Google a aussi mis en place un algorithme (appelé PageRank) qui repose sur la popularité : plus une page est signalée par des liens dans d'autres sites, mieux elle sera classée. Ce principe a été repris par d'autres moteurs commerciaux.
L’apprentissage automatique et l’intelligence artificielle assistent depuis le milieu des années 2010 l’appariement entre documents et requêtes ainsi que le classement des résultats en tenant compte de différents critères pour cerner le contexte (c’est, par exemple, l’algorithme RankBrain de Google).
L'interface d'interrogation
L'interface d'interrogation est la seule partie visible du moteur de recherche pour l'utilisateur. Elle permet de formuler la demande et de consulter les résultats. Deux types d'interfaces sont souvent proposés : une interface de recherche simple, composée d'une barre de recherche et d'un ou plusieurs boutons ; une interface de recherche avancée où l'on peut préciser sa requête en choisissant des options. Une fois la recherche lancée, deux catégories de liens apparaissent dans les pages de résultats : les résultats éditoriaux ou « naturels » et les annonces publicitaires. Chaque résultat de la liste correspond à l’adresse du document cible, accompagnée du titre de la page et d'un court fragment de texte montrant les mots recherchés.
Les liens publicitaires ont souvent une relation avec les mots choisis par l'internaute dans sa requête, une publicité « pertinente » qui est assez bien tolérée par les internautes mais aussi parfois confondue avec les résultats éditoriaux. Depuis 2005, les moteurs ont reçu des directives pour faire en sorte de les distinguer plus clairement, en les affichant dans une colonne séparée ou en haut de la page.
Les moteurs de recherche Web les plus connus ont très vite intégré, grâce à l'intelligence artificielle et à l'apprentissage automatique, des fonctionnalités avancées : propositions orthographiques, suggestions de requêtes, traduction automatique, génération de résumés donnant directement une réponse... En effet, de plus en plus, les moteurs cherchent à répondre directement aux questions par un court texte avant de proposer des liens vers des documents sources. Par exemple, depuis 2012, en réponse à certaines questions, Google affiche un encadré accolé à la liste des résultats pour résumer les renseignements supposés essentiels : c’est le Knowledge Graph. Une telle fonctionnalité est rendue possible par l’intelligence artificielle générative qui permet de composer des textes ou images à partir de l’analyse d’une importante masse de données.
Accédez à l'intégralité de nos articles
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Brigitte SIMONNOT : professeure des Universités émérite, Université de Lorraine, Nancy
Classification
Médias
Infrastructure matérielle des moteurs de recherche
wavebreakmedia/ Shutterstock
Fonctionnement d'un moteur de recherche
Encyclopædia Universalis France
Autres références
-
BIBLIOTHÈQUES NUMÉRIQUES
- Écrit par Yannick MAIGNIEN
- 5 199 mots
- 1 média
 ...compression graphique et d'image – MPEG –, encapsulant des métadonnées complexes, va dans le sens de cette intégration des documents textuels scannérisés. Actuellement, si l'OCR reste parfois approximative, elle s'avère suffisante pour des moteurs de recherchestatistique qui localiseront ensuite...
...compression graphique et d'image – MPEG –, encapsulant des métadonnées complexes, va dans le sens de cette intégration des documents textuels scannérisés. Actuellement, si l'OCR reste parfois approximative, elle s'avère suffisante pour des moteurs de recherchestatistique qui localiseront ensuite... -
CONSOMMATION - Comportement du consommateur
- Écrit par Bernard DUBOIS et Marc VANHUELE
- 9 032 mots
- 1 média
 ...emprise. Mais, dans tous les cas, savoir qui sont les consommateurs ayant considéré qu’ils ont un besoin plus ou moins urgent est évidemment très utile. Les moteurs de recherche sur Internet ont révolutionné le marketing parce que c’est là que les consommateurs signalent de plus en plus souvent leurs besoins....
...emprise. Mais, dans tous les cas, savoir qui sont les consommateurs ayant considéré qu’ils ont un besoin plus ou moins urgent est évidemment très utile. Les moteurs de recherche sur Internet ont révolutionné le marketing parce que c’est là que les consommateurs signalent de plus en plus souvent leurs besoins.... -
INTERNET - Les applications
- Écrit par Danièle DROMARD et Dominique SERET
- 5 030 mots
Lesmoteurs de recherche ( Google, Yahoo!, AltaVista...) sont des serveurs spécialisés dans la recherche d'informations sur le Web. Leurs banques de données textuelles sont alimentées en permanence par des programmes automatiques d'indexation qui regroupent par thèmes les informations... -
MÉDECINE ET INTERNET
- Écrit par Philippe MARREL , Elisabeth PARIZEL et René WALLSTEIN
- 5 397 mots
- 3 médias
 ...les recherches. En ce qui concerne Internet, véritable bibliothèque planétaire – on parlerait plutôt de base de données aujourd’hui –, c’est le rôle des moteurs de recherche d’établir le catalogue et d’attribuer les mots clés. Pour cela, le moteur passe systématiquement en revue les millions de sites de...
...les recherches. En ce qui concerne Internet, véritable bibliothèque planétaire – on parlerait plutôt de base de données aujourd’hui –, c’est le rôle des moteurs de recherche d’établir le catalogue et d’attribuer les mots clés. Pour cela, le moteur passe systématiquement en revue les millions de sites de...
Voir aussi
- PROGRAMME, informatique
- FORMES RECONNAISSANCE DES
- DOCUMENT
- ATTEINTES À LA VIE PRIVÉE
- ADRESSE, informatique
- INFORMATION, informatique et télécommunications
- MULTIMÉDIA
- INTERFACE, informatique
- WEB ou WORLD WIDE WEB
- URL (Uniform Resource Locator)
- CONFIDENTIALITÉ, informatique
- NTIC (nouvelles technologies de l'information et de la communication)
- IMAGE ANALYSE DE L'
- MÉTADONNÉES
- WEB SÉMANTIQUE
- REQUÊTE, informatique
- INDEX, informatique
- TECHNIQUES HISTOIRE DES, XXe et XXIe s.
- SYNONYMIE
- INFORMATIQUE DOCUMENTAIRE
- RECONNAISSANCE AUTOMATIQUE DE LA PAROLE
- WEB ROBOT ou WEB CRAWLER ou WEB SPIDER
- GOPHER
- ALIWEB
- MÉTA-MOTEUR DE RECHERCHE
- MOTEURS DE RECHERCHE VERTICAUX
- RÉFÉRENCEMENT WEB
- WEB INVISIBLE
- AGENT CONVERSATIONNEL ou CHATBOT
