PSYCHOMÉTRIE
Article modifié le
La validité des scores
Une autre qualité essentielle des scores à un test est leur validité. On considère généralement qu’un test est valide s’il mesure ce qu’il prétend mesurer. Par exemple, un questionnaire censé évaluer la dépression sera jugé valide s’il mesure bien ce syndrome et rien que celui-ci. Cette première définition simplifie toutefois une notion en réalité plus complexe. La validité n’est en effet pas une propriété générale d’un test, mais plutôt des inférences faites sur la base des scores récoltés à l’aide de ce test. Par exemple, un questionnaire de dépression peut être valide pour identifier ce trouble chez des adultes, mais pas chez des adolescents. De même, un test de mathématiques peut être valide afin d’identifier les élèves compétents pour entamer une formation scientifique, mais pas pour poser un diagnostic de dyscalculie. Pour chaque inférence proposée, des preuves de validité doivent être fournies. Le processus de validation est une démarche d’accumulation de preuves qui peut s’étendre sur toute la durée de vie d’un test. La validité n’étant pas une qualité intrinsèque que posséderait un test, elle n’accompagne pas celui-ci lorsqu’il est adapté dans une autre langue. Pour chaque adaptation du test, des preuves de validité doivent à nouveau être récoltées.
Les preuves de validité sont de différents types. Il n’existe aucune hiérarchie entre elles. Elles viennent chacune se compléter et contribuer à la validation des utilisations et des interprétations des scores d’un test. Les Standards for Educational and PsychologicalTesting (1999), qui sont la référence dans le domaine, rangent les preuves de validité en cinq catégories selon qu’elles sont basées sur : l’analyse du contenu du test ; les processus de réponse au test ; la structure interne du test ; les relations avec d’autres variables et les conséquences de l’utilisation du test. Une brève présentation en est faite ci-dessous.

Les preuves basées sur l’analyse du contenu du test sont rassemblées par des experts du domaine qui vérifient que les items sont bien représentatifs de la caractéristique que prétend mesurer le test. Pour ce faire, les experts doivent s’appuyer sur une définition précise du concept mesuré. Par exemple, des psychiatres se référeront à une définition détaillée du syndrome dépressif pour apprécier si les items d’un questionnaire de dépression évaluent bien les différentes facettes de ce syndrome. Cette évaluation ne se limite pas au strict contenu des items. Elle s’intéresse aussi à la pondération donnée à chacune des facettes du concept, aux consignes données aux répondants, aux modalités de réponse, aux critères de cotation, bref à tous les aspects du test qui peuvent avoir une influence sur les mesures récoltées à l’aide de celui-ci.
Les preuves basées sur les processus de réponse concernent les démarches mises en œuvre par les individus pour répondre aux items du test. Il s’agit de vérifier que les individus mettent effectivement en œuvre les processus cognitifs que l’on souhaite évaluer. En effet, une même réponse à un item peut être le fruit de processus très différents. L’observation d’une réponse exacte n’est dès lors pas suffisante pour prouver que l’on mesure effectivement ce que l’on prétend mesurer. Par exemple, l’évaluation de l’efficience en calcul mental ne peut être validée sur la seule base des réponses exactes. Il est en effet possible que celles-ci soient simplement récupérées en mémoire, sans qu’un calcul mental soit effectué. Pour contrôler que ce soit bien le cas, la mesure du temps de réponse peut être un bon indicateur qui servira de preuve de validité.
Les preuves basées sur la structure interne du test font référence aux relations observées entre les items et/ou les sous-ensembles d’items. La construction d’un test se base toujours sur un modèle d’organisation des items. Le modèle le plus simple est celui d’une échelle unidimensionnelle sur laquelle sont ordonnés tous les items. Dans ce cas, le test ne permet de calculer qu’un seul score global correspondant à la somme des scores à chacun des items. Mais le modèle peut être plus complexe. Par exemple, de nombreux tests d’intelligence sont organisés en sous-échelles, chacune mesurant une facette de l’intelligence et donnant lieu au calcul d’un score propre. Les modèles d’organisation des items sont généralement basés sur une théorie qui justifie a priori l’organisation choisie. Mais encore faut-il prouver de manière empirique que cette organisation est pertinente et que les calculs de scores sont justifiés. Pour ce faire, il est nécessaire d’analyser les liaisons observées entre les items. Généralement, le point de départ de cette analyse est la matrice de corrélations entre items, calculées à partir des résultats d’un échantillon de la population de référence. En examinant cette matrice, il est déjà possible de vérifier si le niveau des corrélations correspond à ce qui est prévu par le modèle initial. Par exemple, si le modèle est unidimensionnel, tous les items de l’échelle devraient être bien corrélés entre eux. Si c’est le cas, le calcul et l’interprétation d’un score total seront considérés comme valides. Si, en revanche, le modèle comprend deux échelles indépendantes, les items de la première échelle devraient être bien corrélés entre eux, mais très peu avec les items de l’autre échelle, et réciproquement. Si les différents niveaux de corrélation correspondent à ce qui était prévu par le modèle, le calcul et l’interprétation d’un score pour chacune des deux échelles seront considérés comme valides. Lorsque le niveau des corrélations observées ne correspond pas à ce qui était prévu par le modèle, il est nécessaire de revoir soit le contenu des items, soit la théorie qui sous-tend le modèle, soit les deux. L’évaluation de l’adéquation entre le modèle de référence et les corrélations observées est souvent réalisée à l’aide de l’analyse factorielle. Cette technique consiste à mettre en évidence les variables sous-jacentes, appelées facteurs, qui sous-tendent les relations entre les variables observées. Par exemple, si le modèle de référence est unidimensionnel, on vérifiera qu’un seul facteur permet d’expliquer l’essentiel des relations entre les variables observées.
Les preuves de validité basées sur les relations avec d’autres variables supposent que la caractéristique mesurée par le test puisse l’être de manière valide par d’autres moyens. Si c’est le cas, les mesures prises comme critère devraient être bien corrélées avec les mesures récoltées à l’aide du test. Des corrélations élevées seront considérées comme des indices de validité des scores au test pour la population considérée. Si, par exemple, on souhaite évaluer la validité des scores à un test d’anxiété utilisé avec des personnes âgées, ces personnes seront évaluées par des cliniciens expérimentés qui coteront le degré d’anxiété de chacune d’elles. Les cotations des cliniciens seront ensuite corrélées avec les scores au questionnaire. Si la corrélation est élevée, cela constituera une preuve de validité. Parfois, le critère de référence n’est disponible que dans le futur. C’est le cas lorsque le score au test sert à prédire une performance, laquelle est prise comme critère de validité. Par ailleurs, pour être considéré comme valide, le score au test ne doit pas nécessairement varier dans le même sens que le score au critère. Par exemple, on devrait s’attendre à ce que les performances scolaires varient dans le sens inverse des scores exprimés en temps de réponse ou en nombre d’erreurs à un test d’attention. Si c’est le cas, on observera une corrélation négative qui sera considérée comme une preuve de validité. Cette procédure de validation est relativement simple à mettre en œuvre, mais présente certaines faiblesses. La plus importante est la difficulté de trouver un critère valide. Lorsque la corrélation entre les scores au test et au critère est faible, on ne peut jamais exclure que la validité des scores au critère soit à l’origine de la médiocre corrélation observée.
Les preuves de validité basées sur les conséquences du test ont été introduites assez récemment parmi les indices de validité. L’évaluation des conséquences de l’usage des scores à un test est similaire à celles des effets secondaires d’un médicament. L’évaluation d’une personne à l’aide d’un test peut en effet avoir des conséquences indésirables, parfois supérieures à ses effets positifs. Par exemple, les scores à un test cognitif peuvent être utilisés avec succès pour prédire l’apparition de la maladie d’Alzheimer. Toutefois, cette prédiction reste une probabilité. Dans un certain pourcentage de cas, un score élevé au test ne débouchera pas sur l’apparition de la maladie. Doit-on dès lors prendre le risque d’alerter des personnes qui vont s’inquiéter inutilement ? À partir de quel pourcentage de prédictions correctes va-t-on considérer que les avantages dépassent les inconvénients ? Ce genre d’information est aujourd’hui considéré comme important et devrait être systématiquement pris en compte au sein des indices de validité des scores à un test.
Accédez à l'intégralité de nos articles
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Jacques GRÉGOIRE : docteur en psychologie, professeur d'université
Classification
Média
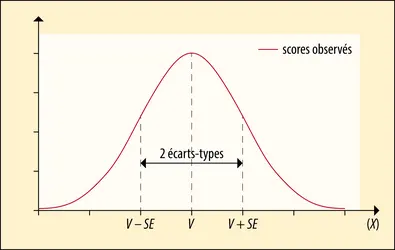
Erreur-type de mesure
Encyclopædia Universalis France
Autres références
-
PSYCHOMÉTRIE (tests et échelles d'évaluation en psychiatrie)
- Écrit par Frédéric ROUILLON
- 3 674 mots
La psychométrie désigne la technique d’évaluation standardisée des phénomènes psychiques. Apparue à la fin du xixe siècle, elle s’est développée à partir du début du xxe siècle, à l’initiative de psychologues, principalement pour la mesure des performances intellectuelles de l’enfant...
-
ALZHEIMER MALADIE D'
- Écrit par Nathalie CARTIER-LACAVE
- 1 872 mots
Cestroubles peuvent être évalués par un test psychométrique le MMSE (Mini Mental State Evaluation) établi sur une échelle de 30 points. Un score inférieur à 24 fait soupçonner la démence. Les résultats des tests sont interprétés en fonction du niveau socio−économique des patients et de leur degré de... -
APPROCHES TRANSVERSALE ET LONGITUDINALE EN PSYCHOLOGIE DU DÉVELOPPEMENT
- Écrit par Henri LEHALLE
- 1 044 mots
S’informer sur le développement des enfants et des adolescents impose de pouvoir comparer leurs comportements aux différents âges. Pour cela, diverses approches méthodologiques sont possibles.
Selon une première approche « transversale », les groupes d’âge à comparer sont constitués par des...
-
ATTENTION
- Écrit par Éric SIÉROFF
- 1 929 mots
Deux grands principes méthodologiques guident la mesure de l’attention, la « chronométrie mentale »et la « méthode soustractive ». Selon la chronométrie, il faut enregistrer les temps de réponse à un stimulus, parce que l’attention module le traitement de l’information en l’accélérant,... -
ATTITUDE
- Écrit par Raymond BOUDON
- 4 176 mots
- 2 médias
 Parce qu'elle implique l'idée de degré ou d'intensité, la notion d'attitude soulève un problème méthodologique important : celui de la détermination de cette intensité. On parle alors de la « mesure des attitudes ». À première vue, le problème prend l'allure d'un défi. Comment, en effet, mesurer ce...
Parce qu'elle implique l'idée de degré ou d'intensité, la notion d'attitude soulève un problème méthodologique important : celui de la détermination de cette intensité. On parle alors de la « mesure des attitudes ». À première vue, le problème prend l'allure d'un défi. Comment, en effet, mesurer ce... - Afficher les 35 références
Voir aussi
