
REPRODUCTIBILITÉ EN SCIENCES EXPÉRIMENTALES
Article modifié le
Le soupçon de la fraude
Cet embellissement, le terme étant alors entendu au sens littéral, peut prendre la forme d'une retouche des images présentées à l'appui des résultats dans les articles scientifiques. En soumettant les clichés numériques accompagnant les articles qui leur étaient présentés au test de logiciels spécialisés, les éditeurs du Journal of CellBiology, importante revue de biologie cellulaire, ont constaté que le quart d'entre eux avaient été retouchés, à un point tel que, dans 10 p. 100 des manuscrits, les manipulations relevaient de la fraude. Le même constat a été fait par le rédacteur en chef de la revue OrganicLetters, dans le domaine de la chimie organique, les retouches ne portant plus alors sur des clichés de microscopie mais sur des spectres d'analyse, en particulier pour en éliminer les traces d'impuretés.
Une autre manière d'embellir les données est d'en manipuler les statistiques, un phénomène particulièrement bien documenté dans le domaine de la psychologie expérimentale. Lorsqu'il conduit une série d'expériences, un chercheur teste le plus souvent une hypothèse. Il mesure un certain nombre de fois (n) tel ou tel phénomène et cherche à savoir si son hypothèse permet de rendre compte des n résultats obtenus. Cependant, les variations du phénomène qu'il observe peuvent être aléatoires. La communauté scientifique admet généralement qu'un résultat est pertinent si l'on peut calculer qu'il y a moins d'une chance sur vingt qu'il soit dû au hasard. Les scientifiques notent cette probabilité statistique p. Ce seuil de p ˂ 0,05 (1 sur 20) est arbitraire. Notons au passage que cet usage entraîne automatiquement qu'au moins une étude scientifique sur vingt peut être fausse.
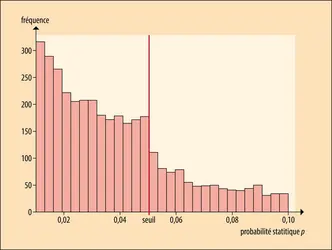
Preuve graphique d'une fraude scientifique
Encyclopædia Universalis France
Deux psychologues nord-américains ont étudié les valeurs de p rapportées dans les expériences décrites de quelque 3 557 publications parues en 2008 dans trois revues respectées du domaine de la psychologie expérimentale. Ils ont observé que les valeurs de p comprises entre 0,045 et 0,050 – soit juste sous le seuil retenu pour faire d'une expérience une observation publiable – sont surreprésentées. Avec un pic particulièrement net entre 0,048 75 et 0,050 00, qui incite fortement à penser que les données ont été arrangées pour passer juste sous le seuil fatidique. Plusieurs manipulations sont possibles pour obtenir ce p juste inférieur à 0,05. On peut par exemple sélectionner de préférence les expériences jugées concluantes. On peut aussi décider d'arrêter la collecte de données quand les résultats obtenus permettent d'obtenir le fameux p ˂ 0,05, car poursuivre celle-là risquerait de s'en éloigner.
L'explosion des capacités de calcul, qui donne à un ordinateur de bureau la puissance d'un supercalculateur des années 1970, a sans doute contribué à amplifier la propension à arranger les résultats expérimentaux pour qu'ils soient juste significatifs. Avant leur apparition dans le quotidien des laboratoires, le calcul de p se faisait à l'aide de tables listant, pour les différentes proportions possibles de valeurs expérimentales, les intervalles de p correspondants. Aujourd'hui, on n'obtient plus un intervalle mais, en un clic, la valeur précise à plusieurs décimales près. Il devient alors très simple d'enlever quelques valeurs obtenues expérimentalement pour voir si p pourrait passer sous la valeur seuil de 0,05.
Une équipe de psychologues australiens a comparé les valeurs de p dans les articles publiés dans The Journal of Personality and Social Psychology en 1965 à celles des articles parus en 2005. Pour cette dernière année, si l'on recalcule la valeur de p, sur la base des résultats publiés, on trouve que 38 p. 100 d'entre eux l'ont sous-estimée. La propension à trouver des valeurs[...]
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Nicolas CHEVASSUS-au-LOUIS : docteur en biologie, journaliste
Classification
Média
Preuve graphique d'une fraude scientifique
Encyclopædia Universalis France
Voir aussi
