
SYSTÈMES INFORMATIQUES Systèmes d'aide à la décision
Article modifié le
L' information est la matière première la plus précieuse pour la compétitivité des entreprises au xxie siècle et l'intelligence – humaine ou artificielle – a besoin de cette connaissance pour aider à la prise de décision. Le partage de données et la diffusion de connaissance sont donc les domaines les plus sollicités de l'informatique dans tous les domaines d'activité, de la grande distribution à la recherche médicale. Les systèmes d'information ont permis, à partir des années 1970, d'optimiser les activités de production de l'entreprise, ils ont aussi permis d'engranger dans les bases de données de véritables « gisements » d'informations. L'idée s'est alors faite dès les années 1980, en particulier grâce aux travaux de Ralph Kimball, de les utiliser à des fins décisionnelles et de les organiser pour en extraire de précieux renseignements.
En 1994, William Inmon a formalisé le concept d'entrepôt de données (en anglais data warehouse) : « Un entrepôt de données est une collection de données thématiques, intégrées, non volatiles et historisées, organisées pour le support à la prise de décision ». Jean-François Goglin définit un entrepôt de données comme un stockage intermédiaire de données issues des applications de production, dans lequel les utilisateurs finaux puisent avec des outils de restitution et d'analyse. Cette dernière définition résume bien toute la « chaîne décisionnelle » que suivent les données pour devenir des informations dont la connaissance améliorera les résultats de l'entreprise.
Nous détaillerons d'abord les différents processus de la chaîne décisionnelle, en particulier celui de l'intégration sémantique des données, qui représente la tâche la plus complexe de la chaîne. Puis nous présenterons le modèle OLAP, proposé par Edgar F. Codd, spécialement conçu pour la diffusion des informations à des fins décisionnelles. Enfin, nous montrerons les différents types de restitutions pour la business intelligence, dont l'objet est l'exploitation de cette information pour constituer une base de connaissance.
Architecture générale d'un entrepôt de données
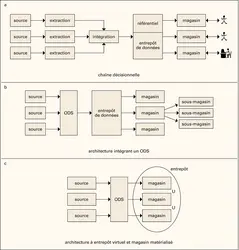
Systèmes décisionnels : chaîne décisionnelle et entrepôt de données
Encyclopædia Universalis France
L' idée générale de la chaîne décisionnelle (fig. 1a) est de fournir aux décideurs, sous une forme appropriée, les informations qui vont les aider à prendre les décisions.
La chaîne décisionnelle
Les données sont extraites à partir des sources puis stockées dans un entrepôt de données. On duplique les données pour ne pas travailler directement sur les sources, cela pour trois raisons :
– L'historisation des données sur de nombreuses années est un point capital de l'entrepôt. C'est à partir de l'historique que des extrapolations pourront être faites. Aucune suppression de donnée n'est effectuée dans l'entrepôt, ce qui implique que l'attribut date soit présent dans toutes les relations pour indiquer le début et la fin de validité d'une donnée. Cela permet par exemple de suivre le comportement d'un client au fil des changements qui peuvent intervenir dans sa vie ;
– Les interrogations effectuées à des fins décisionnelles font généralement intervenir un très grand nombre d'enregistrements (par exemple le calcul de toutes les ventes sur plusieurs années) et perturberaient gravement les performances des traitements de production ;
– Pour optimiser les temps de réponse, les requêtes effectuées par les applications de productions pour lesquelles ont été conçues les bases de données ne nécessitent pas les mêmes choix d'organisation à la fois logiciels (schéma physique de la base de données) et matériels (logiciels de stockage).
Les sources
La notion d'entrepôt de données est fondée sur le postulat que l'entreprise regorge de données stockées momentanément – pour des besoins[...]
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Elisabeth METAIS : professeur des Universités en informatique au Conservatoire national des arts et métiers, Paris
Classification
Médias
Systèmes décisionnels : chaîne décisionnelle et entrepôt de données
Encyclopædia Universalis France
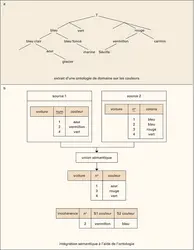
Systèmes décisionnels : ontologie
Encyclopædia Universalis France

Systèmes décisionnels : cube OLAP
Encyclopædia Universalis France
Voir aussi
- STANDARDISATION
- INFORMATION, informatique et télécommunications
- DÉCISION
- MÉTADONNÉES
- ONTOLOGIE, informatique
- SQL (Structured Query Language)
- REQUÊTE, informatique
- ENTREPÔT DE DONNÉES
- AIDE À LA DÉCISION, informatique
- EXTRACTION DE DONNÉES, informatique
- INTÉGRATION SÉMANTIQUE DES DONNÉES, informatique
- RÉFÉRENTIEL, informatique
- MAGASIN DE DONNÉES
- OLTP (On-Line Transaction Processing)
- OLAP (On-Line Analytical Processing)
- MOLAP (multidimensional OLAP)
- ROLAP (relational OLAP)
- HOLAP (hybrid OLAP)
- HYPERCUBE OLAP
- MDX (multidimensional expression)
- DATA MINING
- INFORMATIQUE DÉCISIONNELLE
- SYSTÈMES D'INFORMATION
- SGBD (système de gestion de base de données)
- BASE DE DONNÉES
