
- 1. Notions de base de données et de système de gestion de bases de données
- 2. Bref historique et typologie
- 3. Le modèle relationnel
- 4. Accès aux données
- 5. Accès concurrent et transactions
- 6. Données semi-structurées et documents XML
- 7. Une nouvelle vision des données
- 8. Un domaine plein de vitalité, à la frontière de nombreuses autres disciplines
- 9. Bibliographie
SYSTÈMES INFORMATIQUES Systèmes de gestion de bases de données
Bref historique et typologie
Les premiers S.G.B.D. sont apparus dans les années 1960 lorsqu'on s'est rendu compte que pour stocker les données d'une application sur des fichiers il fallait, chaque fois, un grand effort pour l'encodage et la gestion des informations. L'utilisation de formats de fichiers spécifiques à chaque application était également une barrière importante pour le partage d'informations entre plusieurs applications. L'idée principale fut alors d'introduire, entre le système d'exploitation et les applications, une couche de logiciel spécialisée dans la gestion de données structurées. L'un des premiers systèmes de grande ampleur à implanter une telle couche fut le système IMS avec le langage DL/1 (data language one), basé sur un modèle hiérarchique pour la représentation des données. Parallèlement, le Database Task Group (fondé par Charles Bachman) définit la norme CODASYL, qui s'appuie sur une structuration des informations en réseaux. Les deux paradigmes (hiérarchie et réseau) étaient fondés sur des langages navigationnels qui nécessitaient une connaissance fine de la structuration des données pour leur exploration et leur interrogation. En 1970, Ted Codd (A. M. Turing Award 1981), proposa de faciliter et d'optimiser l'interaction avec les S.G.B.D. en utilisant le modèle relationnel pour la représentation des données. Dans ce modèle ensembliste, l'information est organisée en plusieurs tables ou relations homogènes qui peuvent être interrogées et combinées grâce à des opérateurs ensemblistes. Le succès du modèle relationnel dans les S.G.B.D. modernes tient à sa simplicité (on n'est pas obligé de connaître les détails d'implémentation pour interroger la base), ses fondements logiques et son efficacité (il existe des algorithmes et des structures de données efficaces pour manipuler les données). Dans les années 1990, est apparu un nouveau type de modèles de données, les modèles semi-structurés, mieux adaptés à la gestion et à l'intégration de documents hétérogènes tels qu'ils sont publiés sur le Web. Le standard XML est un représentant de ce type de modèles.
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Bernd AMANN : professeur des Universités
- Michel SCHOLL : professeur des Universités, Conservatoire national des arts et métiers, laboratoire Cédric
Classification
Médias
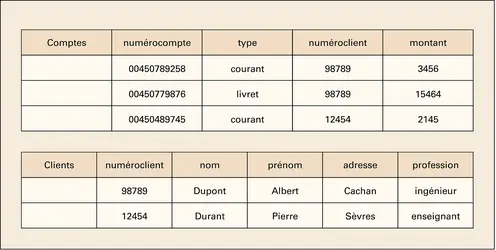
S.G.B.D. relationnel : exemples de relations
Encyclopædia Universalis France
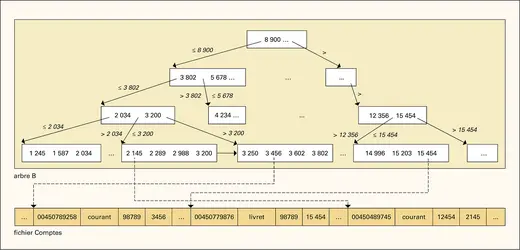
S.G.B.D. relationnel : fichier Comptes et arbre B
Encyclopædia Universalis France
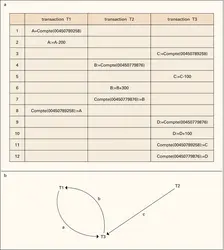
S.G.B.D. relationnel : accès concurrent et transactions
Encyclopædia Universalis France
